对文本转语音 (text-to-speech, TTS) 模型的质量进行自动度量非常困难。虽然评估声音的自然度和语调变化对人类来说是一项微不足道的任务,但对人工智能来说要困难得多。为了推进这一领域的发展,我们很高兴推出 TTS 擂台。其灵感来自于 LMSys 为 LLM 提供的
动机
长期以来,语音合成领域缺乏准确的方法以度量不同模型的质量。常用客观指标 (如 WER (word error rate,单词错误率) 等) 并不能可靠地度量模型质量,而 MOS (mean opinion score,平均意见得分) 等主观指标通常只适用于对少数听众进行小规模实验。因此,这些评估标准在对质量大致相当的两个模型进行比较时并无用武之地。为了解决这些问题,我们设计了易用的界面,并邀请社区在界面上对模型进行排名。通过开放这个工具并公开评估结果,我们希望让人人都参与到模型比较和选择中来,并共享其结果,从而实现模型排名方式的民主化。
TTS 擂台
由人类来对人工智能系统进行排名并不是什么新方法。最近,LMSys 在其 Chatbot 擂台 中采用了这种方法,取得了很好的效果,迄今为止已收集到超过 30 万个投票。被它的成功所鼓舞,我们也采用了类似的框架,邀请每个人投票参与音频合成效果的排名。
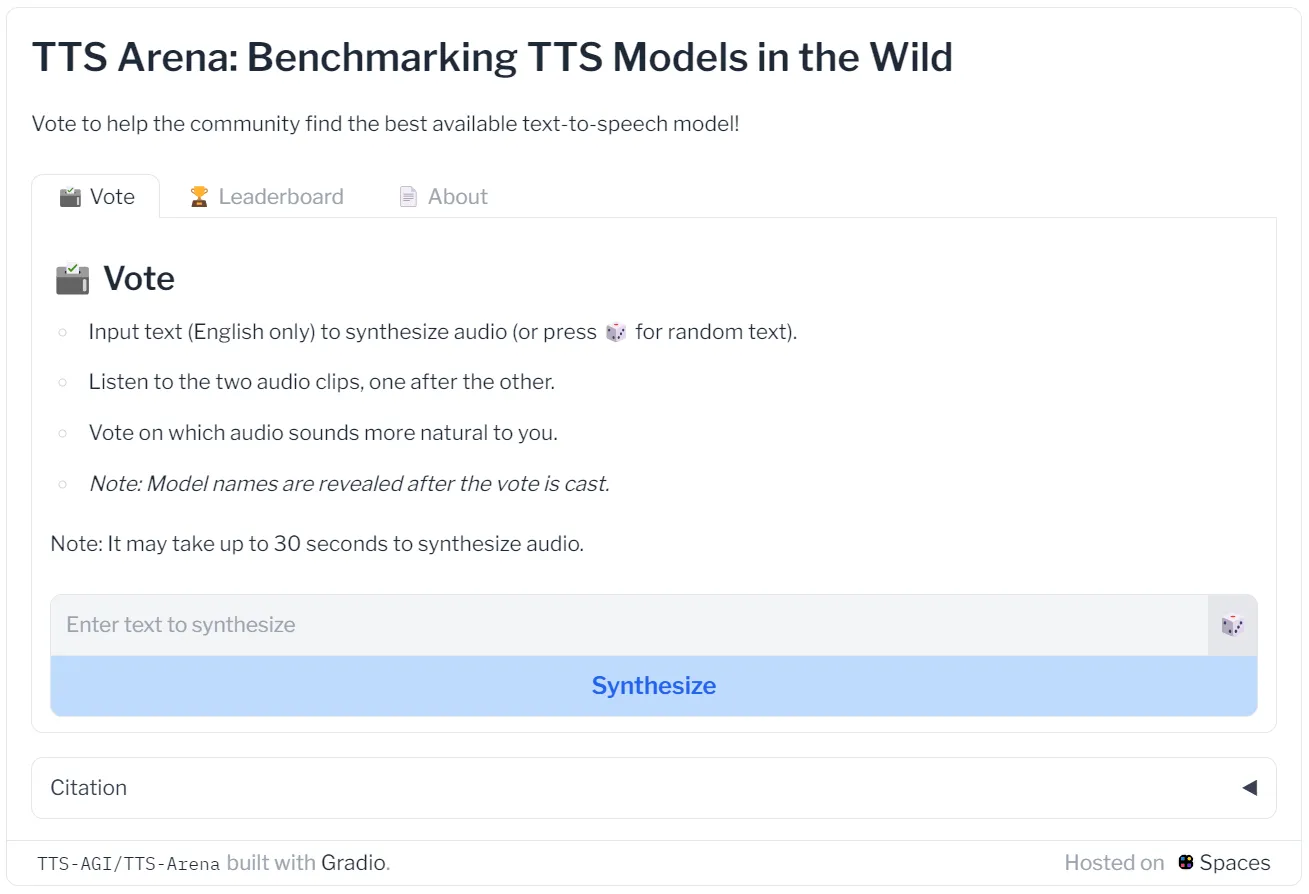
具体方法很简单: 用户输入文本,会有任意两个模型对该文本进行合成; 用户在听完两个合成音频后,投票选出哪个模型的输出听起来更自然。为了规避人为偏见和滥用的风险,只有在提交投票后才会显示模型名称。
目前在打擂的模型
我们为排行榜选择了如下几个最先进 (SOTA) 的模型。其中大多数都是开源模型,同时我们还纳入了几个私有模型,以便开发人员可以对开源社区与私有模型各自所处的状态进行比较。
首发的模型有:
尽管还有许多其他开源或私有模型,我们首发时仅纳入了一些被普遍认同的、最高质量的公开可用模型。
TTS 排行榜
我们会将擂台票选结果公开在专门的排行榜上。请注意,每个模型只有积累了足够的投票数后才会出现在排行榜中。每次有新的投票时,排行榜都会自动更新。
跟 Chatbot 擂台一样,我们使用与 Elo 评级系统类似的算法对模型进行排名,该算法常用于国际象棋以及一些其他游戏中。
总结
我们希望 TTS 擂台 能够成为所有开发者的有用资源。我们很想听听你的反馈!如果你有任何问题或建议,请随时给我们发送 X/Twitter 私信 或在 擂台 Space 的社区中开个帖子 和我们讨论。
致谢
非常感谢在此过程中给予我们帮助的所有人,包括 Clémentine Fourrier、Lucian Pouget、Yoach Lacombe、Main Horse 以及整个 Hugging Face 团队。特别要感谢 VB 的时间及技术协助。还要感谢 Sanchit Gandhi 和 Apolinário Passos 在开发过程中提供的反馈及支持。
赞赏
 微信赞赏
微信赞赏 支付宝赞赏
支付宝赞赏
相关文章

