数据好合: Argilla 和 Hugging Face Spaces 携手赋能社区合力构建更好的数据集
最近,Argilla 和 Hugging Face 共同 推出 了 Data is Better Together 计划,旨在凝聚社区力量协力构建一个对提示进行排名的偏好数据集。仅用几天,我们就吸引了:
- 350 个社区贡献者参与数据标注
- 超过 11,000 个提示评分
你可通过 进度面板 了解最新的统计数据!
基于此,我们发布了 10k_prompts_ranked 数据集,该数据集共有 1 万条提示,其中每条提示都附带用户的质量评分。我们希望后续能开展更多类似的项目!
本文将讨论为什么我们认为社区合作构建数据集至关重要,并邀请大家作为首批成员加入社区,Argilla 和 Hugging Face 将共同支持社区开发出更好的数据集!
“无数据,不模型”仍是颠扑不破的真理
数据对于训练出更好的模型仍具有至关重要的作用: 现有的研究 及开源 实验 不断地证明了这一点,开源社区的实践也表明更好的数据才能训练出更好的模型。

为什么需要社区合力构建数据集?
“数据对于机器学习至关重要”已获得广泛共识,但现实是对很多语言、领域和任务而言,我们仍然缺乏用于训练、评估以及基准测试的高质量数据集。解决这一问题的路径之一是借鉴 Hugging Face Hub 的经验,目前,社区已通过 Hugging Face Hub 共享了数千个模型、数据集及演示应用,开放的 AI 社区协力创造了这一令人惊叹的成果。我们完全可以将这一经验推广,促成社区协力构建下一代数据集,从而为构建下一代模型提供独特而宝贵的数据基础。
赋能社区协力构建和改进数据集得好处有:
- 无需任何机器学习或编程基础,人人皆能为开源机器学习的发展作出贡献。
- 可为特定语言创建聊天数据集。
- 可为特定领域开发基准数据集。
- 可创建标注者多样化的偏好数据集。
- 可为特定任务构建数据集。
- 可利用社区的力量协力构建全新的数据集。
重要的是,我们相信凭借社区的协力会构建出更好的数据集,同时也能让那些不会编码的人也能参与进来为 AI 的发展作贡献。
让人人都能参与
之前许多协力构建 AI 数据集的努力面临的挑战之一是如何赋能大家以高效完成标注任务。Argilla 作为一个开源工具,可让大家轻松地为 LLM 或小型特化模型创建数据集,而 Hugging Face Spaces 是一个用于构建和托管机器学习演示应用的平台。最近,Argilla 对 Spaces 上托管的 Argilla 实例增加了对 Hugging Face 账户验证的支持,有了这个,用户现在仅需几秒钟即可开始参与标注任务。
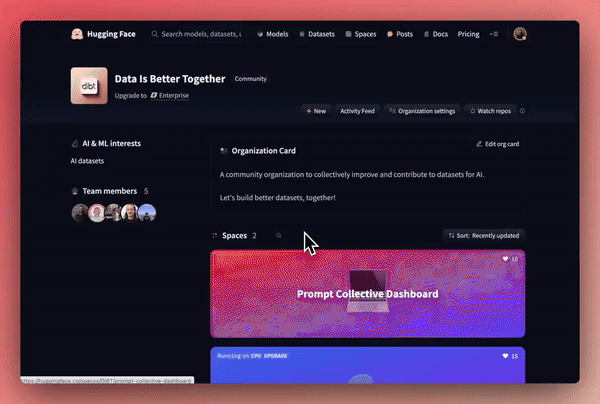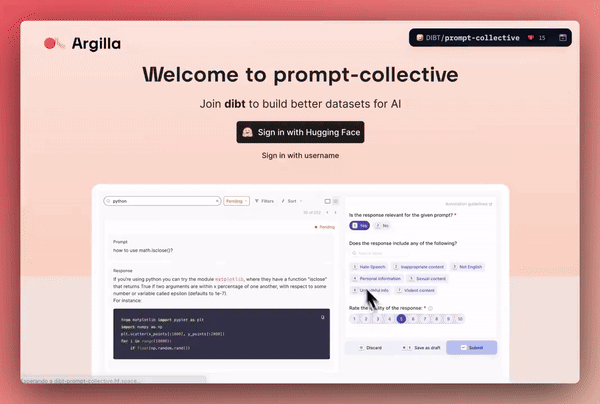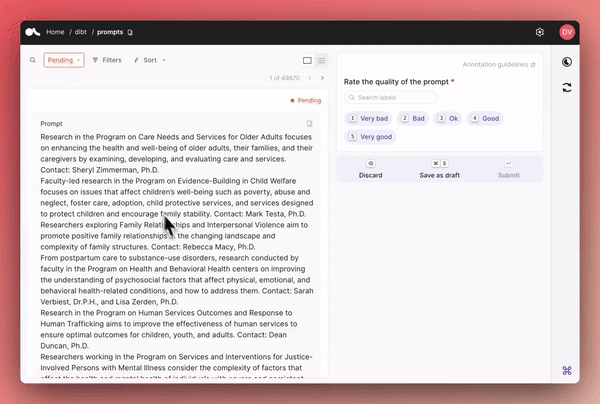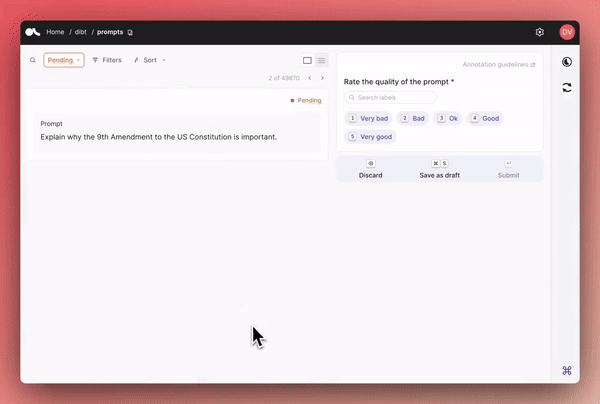
我们在创建 10k_prompts_ranked 数据集时已对这个新的工作流进行了压力测试,我们已准备好支持社区创建新的协作数据集。
首批加入数据集共建社区!
我们对这个新的、简单的托管标注工作流的潜力深感兴奋。为了支持社区构建更好的数据集,Hugging Face 和 Argilla 邀请感兴趣的个人或社区作为首批成员加入我们的数据集构建者社区。
加入这个社区,你将可以:
- 创建支持 Hugging Face 身份验证的 Argilla Space。 Hugging Face 将为参与者提供免费的硬盘和增强型 CPU 资源。
- Argilla 和 Hugging Face 可提供额外的宣传渠道以助力项目宣传。
- 受邀加入相应的社区频道。
我们的目标是支持社区协力构建更好的数据集。我们对所有想法持开放态度,并愿竭尽所能支持社区协力构建更好的数据集。
我们在寻找什么样的项目?
我们愿意支持各种类型的项目,尤其是现存的开源项目。我们对专注于为目前开源社区中数据不足的语言、领域和任务构建数据集的项目尤其感兴趣。当前我们唯一的限制是主要针对文本数据集。如果你对多模态数据集有好想法,我们也很乐意听取你的意见,但我们可能无法在第一批中提供支持。
你的任务可以是完全开放的,也可以是向特定 Hugging Face Hub 组织的成员开放的。
如果你想成为首批成员,请加入 Hugging Face Discord 中的 #data-is-better-together 频道,并告诉我们你想构建什么数据集!
期待与大家携手共建更好的数据集!
赞赏英文原文: https://hf.co/blog/community-datasets
原文作者: Daniel van Strien,Daniel Vila
译者: Matrix Yao (姚伟峰),英特尔深度学习工程师,工作方向为 transformer-family 模型在各模态数据上的应用及大规模模型的训练推理。
 微信赞赏
微信赞赏 支付宝赞赏
支付宝赞赏
相关文章

