我们引入了嵌入量化的概念,并展示了它们对检索速度、内存使用、磁盘空间和成本的影响。我们将讨论理论上和实践中如何对嵌入进行量化,然后介绍一个 演示,展示了 4100 万维基百科文本的真实检索场景。
目录
为什么使用嵌入?
嵌入是自然语言处理中最多样化的工具之一,支持各种设置和使用场景。本质上,嵌入是对更复杂对象 (如文本、图像、音频等) 的数值表示。具体来说,这些对象被表示为 n 维向量。
在转换了复杂对象之后,你可以通过计算相应嵌入的相似性来确定它们的相似性!这对于许多使用场景至关重要: 它为推荐系统、检索、单次学习或少样本学习、异常检测、相似性搜索、释义检测、聚类、分类等提供了基础。
嵌入可能难以扩展
但是,当我们在实际应用中使用嵌入时,可能会遇到一些问题。比如,现在很多先进的模型产生的嵌入都是 1024 维的,每个维度需要 4 字节的空间来存储 (float 32 编码)。如果你要处理 2.5 亿个这样的向量,那就需要大约 1TB 的内存,这既花钱又可能导致处理速度变慢。
下表展示了一些不同的模型,它们的维度大小、需要的内存量以及相应的成本。成本是按照 AWS 上一种叫做 x2gd 的实例来估算的,大概每个月每 GB 需要 3.8 美元。
| 嵌入维数 | 模型样例 | 100M 嵌入 | 250M 嵌入 | 1B 嵌入 |
|---|---|---|---|---|
| 384 | all-MiniLM-L6-v2 bge-small-en-v1.5 |
143.05GB $543 / mo |
357.62GB $1,358 / mo |
1430.51GB $5,435 / mo |
| 768 | all-mpnet-base-v2 bge-base-en-v1.5 jina-embeddings-v2-base-en nomic-embed-text-v1 |
286.10GB $1,087 / mo |
715.26GB $2,717 / mo |
2861.02GB $10,871 / mo |
| 1024 | bge-large-en-v1.5 mxbai-embed-large-v1 Cohere-embed-english-v3.0 |
381.46GB $1,449 / mo |
953.67GB $3,623 / mo |
3814.69GB $14,495 / mo |
| 1536 | OpenAI text-embedding-3-small | 572.20GB $2,174 / mo |
1430.51GB $5,435 / mo |
5722.04GB $21,743 / mo |
| 3072 | OpenAI text-embedding-3-large | 1144.40GB $4,348 / mo |
2861.02GB $10,871 / mo |
11444.09GB $43,487 / mo |
提高可扩展性
有几种方法可以应对嵌入扩展的挑战。最常见的方法是降维,比如使用 主成分分析 (PCA)。然而,传统的降维方法——比如 PCA ——在处理嵌入时往往效果不佳。
最近,有关于 Matryoshka 表征学习 (MRL) 的新闻 (博客),这种方法由 OpenAI 使用,允许更经济的嵌入。使用 MRL 时,只使用前 n 个嵌入维度。这种方法已经被一些开源模型采用,比如 nomic-ai/nomic-embed-text-v1.5 和 mixedbread-ai/mxbai-embed-2d-large-v1。对于 OpenAI 的 text-embedding-3-large 模型,我们看到在 12 倍压缩下性能保留了 93.1 %,而对于 nomic 的模型,在 3 倍压缩下保留了 95.8% 的性能,在 6 倍压缩下保留了 90% 的性能。
然而,还有一种新的方法可以在这个挑战上取得进展; 它不涉及降维,而是减少嵌入中每个个体值的尺寸大小: 量化。我们的量化实验将展示,我们可以在显著加快计算速度并节省内存、存储和成本的同时,保持大量的性能。让我们进一步了解一下吧!
二进制量化
与在模型中减少权重精度的量化不同,嵌入的量化是指对嵌入本身进行的一个后处理步骤。特别是,二进制量化指的是将嵌入中的 float32 值转换为 1 bit ,从而在内存和存储使用上实现 32 倍的减少。
要将 float32 嵌入量化为二进制,我们只需将归一化的嵌入在 0 处进行阈值处理:
$$
f(x)=
\begin{cases}
0 & \text{如果 } x\leq 0\
1 & \text{如果 } x \gt 0
\end{cases}
$$
我们可以使用汉明距离来高效地检索这些二进制嵌入。汉明距离是指两个二进制嵌入在位上不同的位置数量。汉明距离越低,嵌入越接近; 因此,文档的相关性越高。汉明距离的一个巨大优势是它可以用 2 个 CPU 周期轻松计算,允许极快的性能。
Yamada 等人 (2021) 引入了一个重打分步骤,他们称之为 rerank ,以提高性能。他们提议可以使用点积将 float32 查询嵌入与二进制文档嵌入进行比较。在实践中,我们首先使用二进制查询嵌入和二进制文档嵌入检索 rescore_multiplier * top_k 的结果——即双二进制检索的前 k 个结果的列表——然后使用 float32 查询嵌入对这个二进制文档嵌入列表进行重打分。
通过应用这种新颖的重打分步骤,我们能够在减少内存和磁盘空间使用 32 倍的同时,保留高达 ~96% 的总检索性能,并使检索速度提高多达 32 倍。如果没有重打分,我们能够保留大约 ~92.5% 的总检索性能。
Sentence Transformers 中的二进制量化
将一个维度为 1024 的嵌入量化为二进制将得到 1024 比特。实际上,将比特存储为字节要常见得多,因此当我们量化为二进制嵌入时,我们使用 np.packbits 将比特打包成字节。
因此,将一个维度为 1024 的 float32 嵌入量化后,得到一个维度为 128 的 int8 或 uint8 嵌入。下面是两种使用 Sentence Transformers 生成量化嵌入的方法:
from sentence_transformers import SentenceTransformer
# 1. Load an embedding model
model = SentenceTransformer("mixedbread-ai/mxbai-embed-large-v1")
# 2a. Encode some text using "binary" quantization
binary_embeddings = model.encode(
["I am driving to the lake.", "It is a beautiful day."],
precision="binary",
)或者
from sentence_transformers import SentenceTransformer
from sentence_transformers.quantization import quantize_embeddings
# 1. Load an embedding model
model = SentenceTransformer("mixedbread-ai/mxbai-embed-large-v1")
# 2b. or, encode some text without quantization & apply quantization afterwards
embeddings = model.encode(["I am driving to the lake.", "It is a beautiful day."])
binary_embeddings = quantize_embeddings(embeddings, precision="binary")参考:
mixedbread-ai/mxbai-embed-large-v1SentenceTransformer.encodequantize_embeddings
在这里,你可以看到默认的 float32 嵌入和二进制嵌入在形状、大小和 numpy 数据类型方面的差异:
>>> embeddings.shape
(2, 1024)
>>> embeddings.nbytes
8192
>>> embeddings.dtype
float32
>>> binary_embeddings.shape
(2, 128)
>>> binary_embeddings.nbytes
256
>>> binary_embeddings.dtype
int8请注意,你还可以选择 "ubinary" 来使用无符号的 uint8 数据格式将嵌入量化为二进制。这可能取决于你的向量库/数据库的要求。
向量数据库中的二进制量化
| 向量数据库 | 是否支持 | |
|---|---|---|
| Faiss | 是 | |
| USearch | 是 | |
| Vespa AI | 是 | |
| Milvus | 是 | 通过 |
| Qdrant | 二进制量化 | 通过 |
| Weaviate | 二进制量化 |
标量 (int8) 量化
我们使用标量量化过程将 float32 嵌入转换为 int8 。这涉及到将 float32 值的连续范围映射到可以表示 256 个不同级别 (从 -128 到 127) 的 int8 值的离散集合,如下面的图像所示。这是通过使用大量的嵌入校准数据集来完成的。我们计算这些嵌入的范围,即每个嵌入维度的 min 和 max 。从这里,我们计算将每个值分类的步骤 (桶)。
为了进一步提高检索性能,你可以可选地应用与二进制嵌入相同的重打分步骤。重要的是要注意,校准数据集极大地影响性能,因为它定义了量化桶。
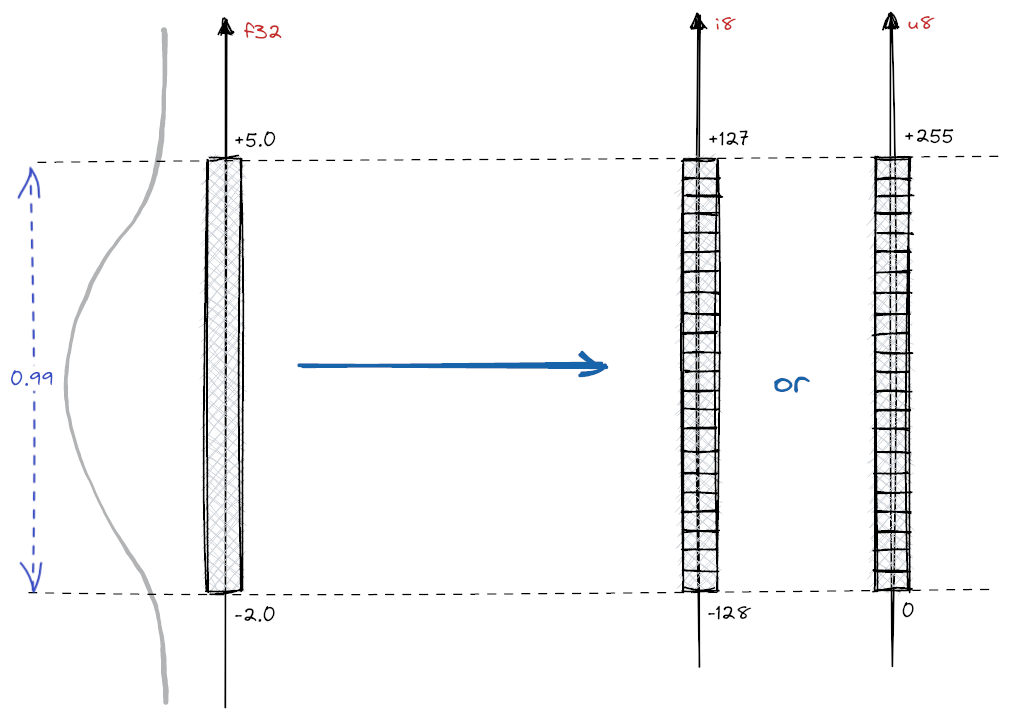
Source: https://qdrant.tech/articles/scalar-quantization/
通过将标量量化为 int8 ,我们将原始 float32 嵌入的精度降低,使得每个值都用一个 8 位整数表示 (缩小 4 倍)。请注意,这与二进制量化情况不同,在二进制量化中,每个值由一个单比特表示 (缩小 32 倍)。
Sentence Transformers 中的标量量化
将一个维度为 1024 的嵌入量化为 int8 将得到 1024 字节。在实际应用中,我们可以选择 uint8 或 int8 。这个选择通常取决于你的向量库/数据库支持哪种格式。
在实践中,建议为标量量化提供以下之一:
- 一大组嵌入,以便一次性全部量化,或者
- 每个嵌入维度的
min和max范围,或者 - 一大组嵌入的校准数据集,从中可以计算
min和max范围。
如果这些情况都不适用,你将收到如下警告:
Computing int8 quantization buckets based on 2 embeddings. int8 quantization is more stable with 'ranges' calculated from more embeddings or a 'calibration_embeddings' that can be used to calculate the buckets.
大意是如果你只使用很少量的嵌入 (在这个例子中是 2 个嵌入) 来计算这些量化桶,那么量化可能不会那么稳定或准确,因为少量的数据可能无法很好地代表整个数据分布。因此,如果你有一个很大的数据集来计算这些范围,或者有一个校准数据集,那么你可以得到更好的量化结果。
请看下面如何使用 Sentence Transformers 生成标量量化嵌入:
from sentence_transformers import SentenceTransformer
from sentence_transformers.quantization import quantize_embeddings
from datasets import load_dataset
# 1. Load an embedding model
model = SentenceTransformer("mixedbread-ai/mxbai-embed-large-v1")
# 2. Prepare an example calibration dataset
corpus = load_dataset("nq_open", split="train[:1000]")["question"]
calibration_embeddings = model.encode(corpus)
# 3. Encode some text without quantization & apply quantization afterwards
embeddings = model.encode(["I am driving to the lake.", "It is a beautiful day."])
int8_embeddings = quantize_embeddings(
embeddings,
precision="int8",
calibration_embeddings=calibration_embeddings,
)参考文献:
mixedbread-ai/mxbai-embed-large-v1SentenceTransformer.encodequantize_embeddings
在这里,你可以看到默认的 float32 嵌入和 int8 标量嵌入在形状、大小和 numpy 数据类型方面的差异:
>>> embeddings.shape
(2, 1024)
>>> embeddings.nbytes
8192
>>> embeddings.dtype
float32
>>> int8_embeddings.shape
(2, 1024)
>>> int8_embeddings.nbytes
2048
>>> int8_embeddings.dtype
int8向量数据库中的标量量化
| 向量数据库 | 是否支持标量量化 | |
|---|---|---|
| Faiss | IndexHNSWSQ | |
| USearch | 是 | |
| Vespa AI | 是 | |
| OpenSearch | 是 | |
| ElasticSearch | 是 | 间接通过 |
| Milvus | IVF_SQ8 | 间接通过 |
| Qdrant | Scalar Quantization |
结合二进制和标量量化
结合二进制和标量量化可以兼得两者的优点: 二进制嵌入的极快速度和标量嵌入在重打分后的优良性能的保留。请查看下面的 演示,这是一个涉及维基百科 4100 万文本的真实实现。该设置的流程如下:
- 使用
mixedbread-ai/mxbai-embed-large-v1SentenceTransformer 模型对查询进行嵌入。 - 使用
sentence-transformers库中的quantize_embeddings函数将查询量化为二进制。 - 使用量化查询在二进制索引 (4100 万个二进制嵌入; 5.2GB 内存/磁盘空间) 中搜索前 40 个文档。
- 从磁盘上的 int8 索引 (4100 万个 int8 嵌入; 0 字节内存,47.5GB 磁盘空间) 动态加载前 40 个文档。
- 使用 float32 查询和 int8 嵌入对前 40 个文档进行重打分,以获得前 10 个文档。
- 按分数对前 10 个文档进行排序并显示。
通过这种方法,我们为索引使用了 5.2GB 内存和 52GB 磁盘空间。这比通常的检索所需的 200GB 内存和 200GB 磁盘空间要少得多。尤其是当你进一步扩展时,这将显著减少延迟和成本。
量化实验
我们在 MTEB 的检索子集上进行了实验,该子集包含 15 个基准测试。首先,我们使用 rescore_multiplier 为 4 来检索前 k (k=100) 个搜索结果。因此,我们总共检索了 400 个结果,并对这前 400 个结果进行了重打分。对于 int8 性能,我们直接使用了点积,而没有进行任何重打分。
| 模型 | 嵌入维度 | 250M 嵌入 | MTEB 检索(NDCG@10) | 默认性能的百分比 |
|---|---|---|---|---|
| 开源模型 | ||||
| mxbai-embed-large-v1: float32 | 1024 | 953.67GB $3623 / mo |
54.39 | 100% |
| mxbai-embed-large-v1: int8 | 1024 | 238.41GB $905 / mo |
52.79 | 97% |
| mxbai-embed-large-v1: binary | 1024 | 29.80GB $113.25 / mo |
52.46 | 96.45% |
| e5-base-v2: float32 | 768 | 286.10GB $1087 / mo |
50.77 | 100% |
| e5-base-v2: int8 | 768 | 178.81GB $679 / mo |
47.54 | 94.68% |
| e5-base-v2: binary | 768 | 22.35GB $85 / mo |
37.96 | 74.77% |
| all-MiniLM-L6-v2: float32 | 384 | 357.62GB $1358 / mo |
41.66 | 100% |
| all-MiniLM-L6-v2: int8 | 384 | 89.40GB $339 / mo |
37.82 | 90.79% |
| all-MiniLM-L6-v2: binary | 384 | 11.18GB $42 / mo |
39.07 | 93.79% |
| 专有模型 | ||||
| Cohere-embed-english-v3.0: float32 | 1024 | 953.67GB $3623 / mo |
55.0 | 100% |
| Cohere-embed-english-v3.0: int8 | 1024 | 238.41GB $905 / mo |
55.0 | 100% |
| Cohere-embed-english-v3.0: binary | 1024 | 29.80GB $113.25 / mo |
52.3 | 94.6% |
从我们的量化实验结果中,可以识别出几个关键趋势和好处。正如预期的那样,维度更高的嵌入模型通常每计算生成的存储成本更高,但能实现最佳性能。然而,令人惊讶的是,量化到 int8 已经帮助 mxbai-embed-large-v1 和 Cohere-embed-english-v3.0 在存储使用低于较小维度基模型的情况下实现了更高的性能。
量化好处的显现,在查看二进制模型的结果时更为明显。在这种情况下,1024 维度的模型仍然优于现在存储需求高 10 倍的基模型,而 mxbai-embed-large-v1 在资源需求减少 32 倍后仍能保持超过 96% 的性能。从 int8 进一步量化到二进制的性能损失几乎可以忽略不计。
有趣的是,我们还可以看到 all-MiniLM-L6-v2 在二进制量化上的性能比 int8 量化更强。这可能的原因是校准数据的选择。在 e5-base-v2 上,我们观察到了 维度坍缩 效应,导致模型只使用潜在空间的子空间; 当进行量化时,整个空间进一步坍缩,导致性能损失很大。
这表明量化并不适用于所有嵌入模型。考虑现有基准测试结果并开展实验以确定给定模型与量化的兼容性仍然至关重要。
重打分的影响
在本节中,我们探讨了重打分对检索性能的影响。我们基于 mxbai-embed-large-v1 评估了结果。
二进制重打分
使用二进制嵌入,mxbai-embed-large-v1 在 MTEB 检索上保留了 92.53% 的性能。仅进行重打分而无需检索更多样本,性能提升到了 96.45%。我们实验设置了 rescore_multiplier 从 1 到 10,但没有观察到进一步的性能提升。这表明 top_k 搜索已经检索到了最顶级的候选项,而重打分则正确地重新排列了这些好的候选项。
标量 (Int8) 重打分
我们还评估了 mxbai-embed-large-v1 模型与 int8 重打分,因为 Cohere 表明 Cohere-embed-english-v3.0 在 int8 量化后可以达到 float32 模型的 100% 性能。在这个实验中,我们将 rescore_multiplier 设置为 [1, 4, 10],并得到了以下结果:
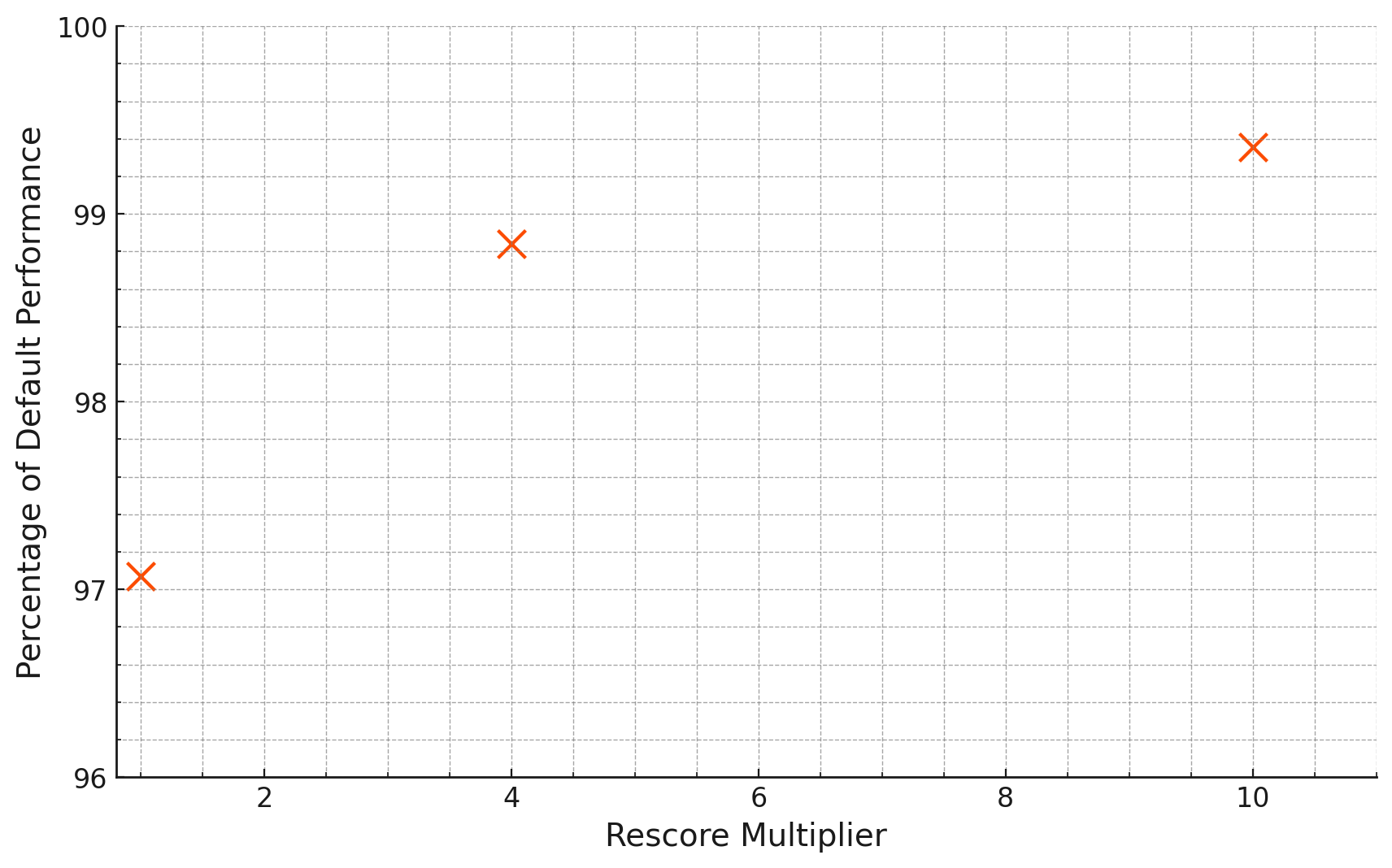
从图表中我们可以看到,更高的重打分乘数意味着量化后性能的更好保留。从我们的结果推断,我们假设这种关系可能是双曲线的,随着重打分乘数的增加,性能接近 100%。使用 int8 时,重打分乘数为 4-5 已经导致令人瞩目的 99% 的性能保留。
检索速度
我们使用 Google Cloud Platform 的 a2-highgpu-4g 实例,在整个 MTEB 检索中测量了 mxbai-embed-large-v1 嵌入的检索速度,该嵌入的维度为 1024。对于 int8 ,我们使用了 USearch (版本 2.9.2) 和二进制量化 Faiss (版本 1.8.0)。所有计算都在 CPU 上使用精确搜索完成。
| 量化 | 最小 | 均值 | 最大 |
|---|---|---|---|
float32 |
1x (baseline) | 1x (baseline) | 1x (baseline) |
int8 |
2.99x speedup | 3.66x speedup | 4.8x speedup |
binary |
15.05x speedup | 24.76x speedup | 45.8x speedup |
如表中所示,应用 int8 标量量化相比全尺寸 float32 嵌入实现了平均速度提升 3.66 倍。此外,二进制量化实现了平均速度提升 24.76 倍。对于标量和二进制量化,即使在最坏的情况下,也实现了非常显著的速度提升。
性能汇总
量化在资源使用、检索速度和检索性能方面的实验结果和影响可以总结如下:
| float32 | int8/uint8 | binary/ubinary | |
|---|---|---|---|
| 内存和索引空间节省 | 1x | 精确 4x | 精确 32x |
| 检索速度 | 1x | 多达 4x | 多达 45x |
| 默认性能百分比 | 100% | ~99.3% | ~96% |
演示
以下 演示 展示了通过结合二进制搜索和标量 ( int8 ) 重打分来提高检索效率。该解决方案需要 5GB 的内存用于二进制索引和 50GB 的磁盘空间用于二进制和标量索引,这比常规的 float32 检索所需的 200GB 内存和磁盘空间要少得多。此外,检索速度也更快。
<iframe
src="https://sentence-transformers-quantized-retrieval.hf.space"
frameborder="0"
width="100%"
height="1000"
自己尝试
以下脚本可用于实验性地进行检索和其他用途的嵌入量化。它们分为三个类别:
-
推荐检索:
- semantic_search_recommended.py: 此脚本结合了二进制搜索和标量重打分,与上面的演示类似,以实现廉价、高效且性能良好的检索。
-
使用:
- semantic_search_faiss.py: 此脚本展示了使用 FAISS 的常规二进制或标量量化、检索和重打分的使用方式,通过使用
semantic_search_faiss实用函数。 - semantic_search_usearch.py: 此脚本展示了使用 USearch 的常规二进制或标量量化、检索和重打分的使用方式,通过使用
semantic_search_usearch实用函数。
- semantic_search_faiss.py: 此脚本展示了使用 FAISS 的常规二进制或标量量化、检索和重打分的使用方式,通过使用
-
基准测试:
- semantic_search_faiss_benchmark.py: 此脚本包括了对
float32检索、二进制检索加重打分和标量检索加重打分的检索速度基准测试,使用 FAISS。它使用了semantic_search_faiss实用函数。我们的基准测试特别显示了ubinary的速度提升。 - semantic_search_usearch_benchmark.py: 此脚本包括了对
float32检索、二进制检索加重打分和标量检索加重打分的检索速度基准测试,使用 USearch。它使用了semantic_search_usearch实用函数。我们的实验在新硬件上显示了巨大的速度提升,特别是对于int8。
- semantic_search_faiss_benchmark.py: 此脚本包括了对
未来工作
我们期待二进制量化技术的进一步发展。要提到的一些潜在改进,我们怀疑可能还有比 int8 更小的标量量化空间,即使用 128 或 64 个桶而不是 256 个。
此外,我们也很兴奋地发现,嵌入量化与 Matryoshka 表征学习 (MRL) 完全垂直。换句话说,可以将 MRL 嵌入从例如 1024 减少到 128 (通常与 2% 的性能降低相对应),然后应用二进制或标量量化。我们怀疑这可能会将检索速度提高多达 32 倍,质量降低约 3%,或者质量降低约 10% 时检索速度提高多达 256 倍。
最后,我们意识到,使用嵌入量化进行检索可以与一个独立的重新排序模型结合起来使用。我们设想了一个三步流水线: 首先进行二进制搜索,然后对结果进行标量 (int8) 重打分,最后使用交叉编码模型进行重新排序。这样的流水线可以实现高效的检索性能,同时降低延迟、内存使用、磁盘空间和成本。
致谢
这个项目得益于我们与 mixedbread.ai 的合作以及 SentenceTransformers 库,该库允许你轻松创建句子嵌入并进行量化。如果你想在你的项目中使用量化嵌入,你现在知道该怎么做了!
引用
@article{shakir2024quantization,
author = { Aamir Shakir and
Tom Aarsen and
Sean Lee
},
title = { Binary and Scalar Embedding Quantization for Significantly Faster & Cheaper Retrieval },
journal = {Hugging Face Blog},
year = {2024},
note = {https://huggingface.co/blog/embedding-quantization},
}参考文献
mixedbread-ai/mxbai-embed-large-v1SentenceTransformer.encodequantize_embeddings
- Sentence Transformers docs – Embedding Quantization
- https://txt.cohere.com/int8-binary-embeddings/
- https://qdrant.tech/documentation/guides/quantization
- https://zilliz.com/learn/scalar-quantization-and-product-quantization
赞赏英文原文:
https://hf.co/blog/embedding-quantization
原文作者: Aamir Shakir, Tom Aarsen, SeanLee
译者: innovation64
 微信赞赏
微信赞赏 支付宝赞赏
支付宝赞赏
相关文章

