欢迎阅读《Hugging Face Transformers 萌新完全指南》,本指南面向那些意欲了解有关如何使用开源 ML 的基本知识的人群。我们的目标是揭开 Hugging Face Transformers 的神秘面纱及其工作原理,这么做不是为了把读者变成机器学习从业者,而是让为了让读者更好地理解 transformers 从而能够更好地利用它。同时,我们深知实战永远是最好的学习方法,因此,我们将以在 Hugging Face Space 中运行 Microsoft 的 Phi-2 LLM 为例,开启我们的 Hugging Face Transformers 之旅。
你可能心里会犯嘀咕,现在市面上已有大量关于 Hugging Face 的教程,为什么还要再搞一个新的呢?答案在于门槛: 大多数现有资源都假定读者有一定的技术背景,包括假定读者有一定的 Python 熟练度,这对非技术人员学习 ML 基础知识很不友好。作为 AI 业务线 (而不是技术线) 的一员,我发现我的学习曲线阻碍重重,因此希望为背景与我相似的学习者提供一条更平缓的路径。
因此,本指南是为那些渴望跳过 Python 学习而直接开始了解开源机器学习的非技术人员量身定制的。无需任何先验知识,从头开始解释概念以确保人人都能看懂。如果你是一名工程师,你会发现本指南有点过于基础,但对于初学者来说,这很合他们胃口。
我们开始吧……,首先了解一些背景知识。
Hugging Face Transformers 是什么?
Hugging Face Transformers 是一个开源 Python 库,其提供了数以千计的预训练 transformer 模型,可广泛用于自然语言处理 (NLP) 、计算机视觉、音频等各种任务。它通过对底层 ML 框架 (如 PyTorch、TensorFlow 和 JAX) 进行抽象,简化了 transformer 模型的实现,从而大大降低了 transformer 模型训练或部署的复杂性。
库是什么?
库是可重用代码段的集合,大家将其集成到各种项目中以有效复用其各种功能,而无需事事都从头实现。
特别地,transformers 库提供的可重用的代码可用于轻松实现基于 PyTorch、TensorFlow 和 JAX 等常见框架的新模型。开发者可以调用库中的函数 (也称为方法) 来轻松创建新的模型。
Hugging Face Hub 是什么?
Hugging Face Hub 是一个协作平台,其中托管了大量的用于机器学习的开源模型和数据集,你可以将其视为 ML 的 Github。该 hub 让你可以轻松地找到、学习开源社区中有用的 ML 资产并与之交互,从而促进共享和协作。我们已将 hub 与 transformers 库深度集成,使用 transformers 库部署的模型都是从 hub 下载的。
Hugging Face Spaces 是什么?
Hugging Face Spaces 是 Hugging Face Hub 上提供的一项服务,它提供了一个易于使用的 GUI,用于构建和部署 Web 托管的 ML 演示及应用。该服务使得用户可以快速构建 ML 演示、上传要托管的自有应用,甚至即时部署多个预配置的 ML 应用。
本文,我们将通过选择相应的 docker 容器来部署一个预配置的 ML 应用程序 (JupyterLab notebook)。
Notebook 是什么?
Notebook 是一种交互式的应用,用户可用它编写并共享一些实时的可执行代码,它还支持代码与文本内容交织在一起。Notebook 对数据科学家和机器学习工程师特别有用,有了它大家可以实时对代码进行实验并轻松查阅及共享结果。
- 创建一个 Hugging Face 账号
- 如果你还没有账号,可至 hf.co,点击
Sign Up以创建新账号。
- 添加账单信息
- 在你的 HF 帐号中,转到
Settings > Billing,在付款信息部分添加你的信用卡信息。
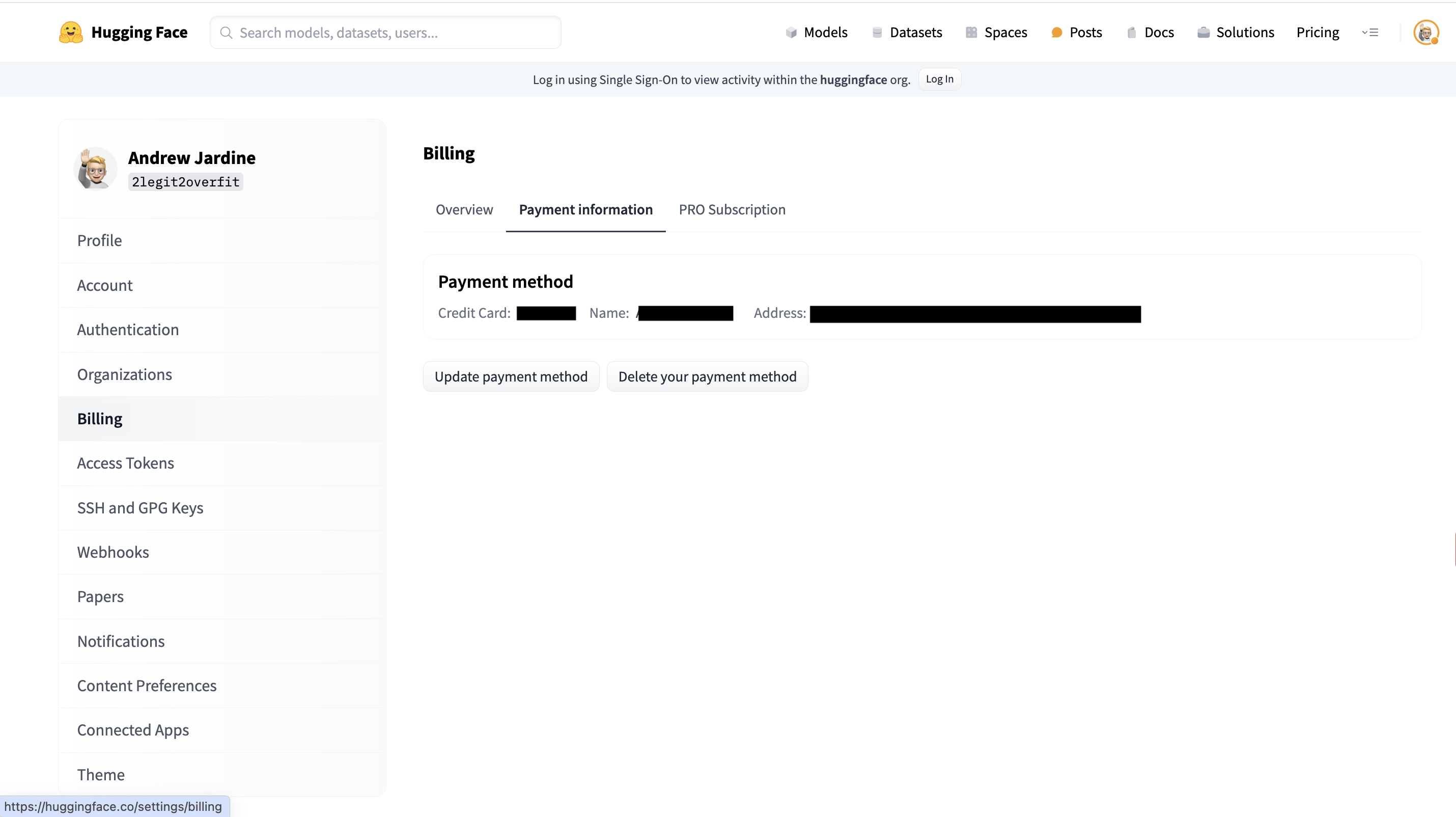
为什么需要信用卡信息?
大多数 LLM 的运行需要用到 GPU,但 GPU 并非是免费的,Hugging Face 提供了 GPU 租赁服务。别担心,并不太贵。本文所需的 GPU 是 NVIDIA A10G,每小时只要几美金。
- 创建一个 Space 以托管你的 notebook
- 在 hf.co 页面点选
Spaces > Create New
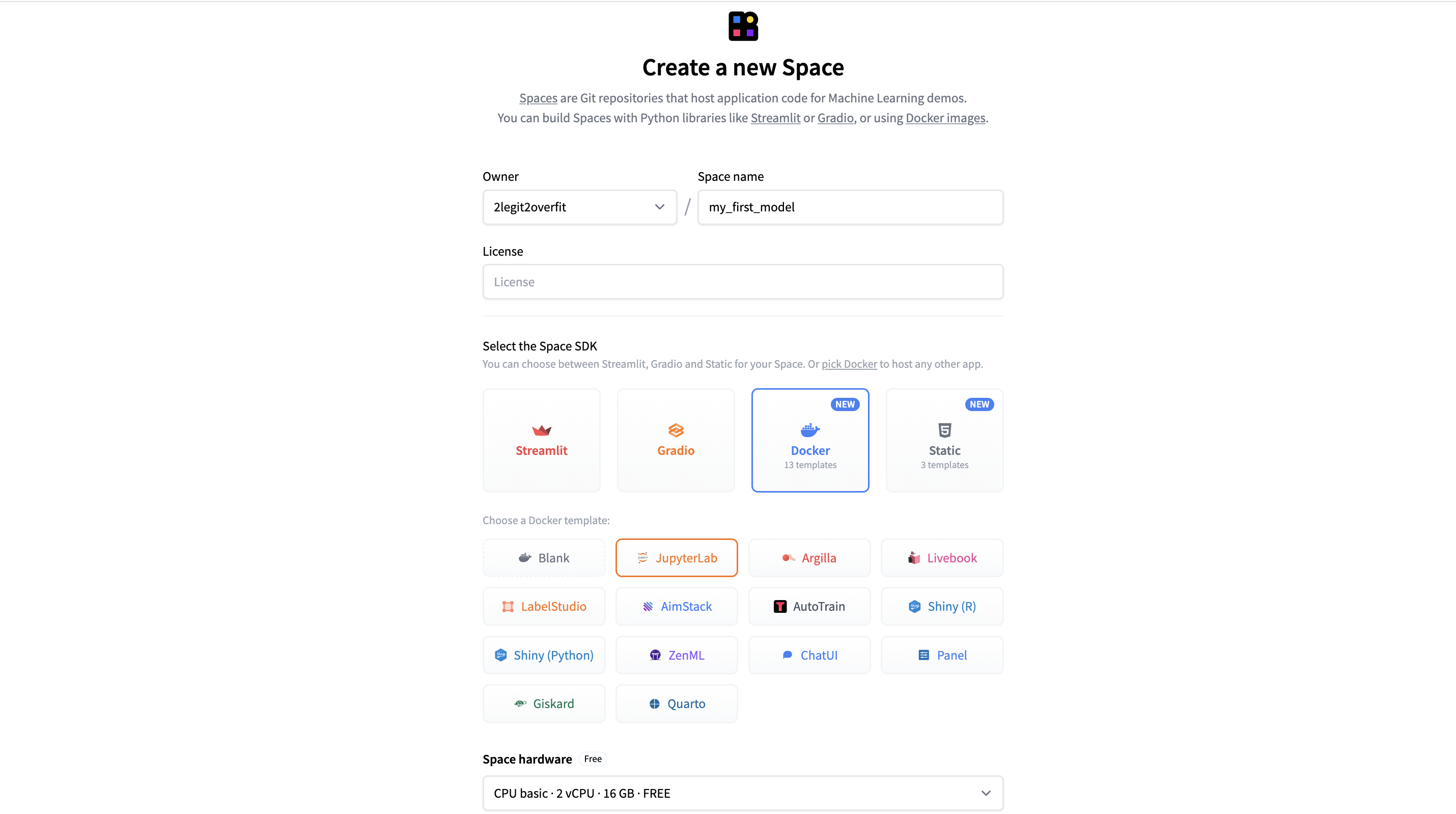
- 配置 Space
- 给你的 Space 起个名字
- 选择
Docker > JupyterLab以新建一个预配置的 notebook 应用 - 将
Space Hardware设为Nvidia A10G Small - 其余都保留为默认值
- 点击
Create Space
Docker 模板是什么?
Docker 模板规定了一个预定义的软件环境,其中包含必要的软件及其配置。有了它,开发人员能够以一致且隔离的方式轻松快速地部署应用。
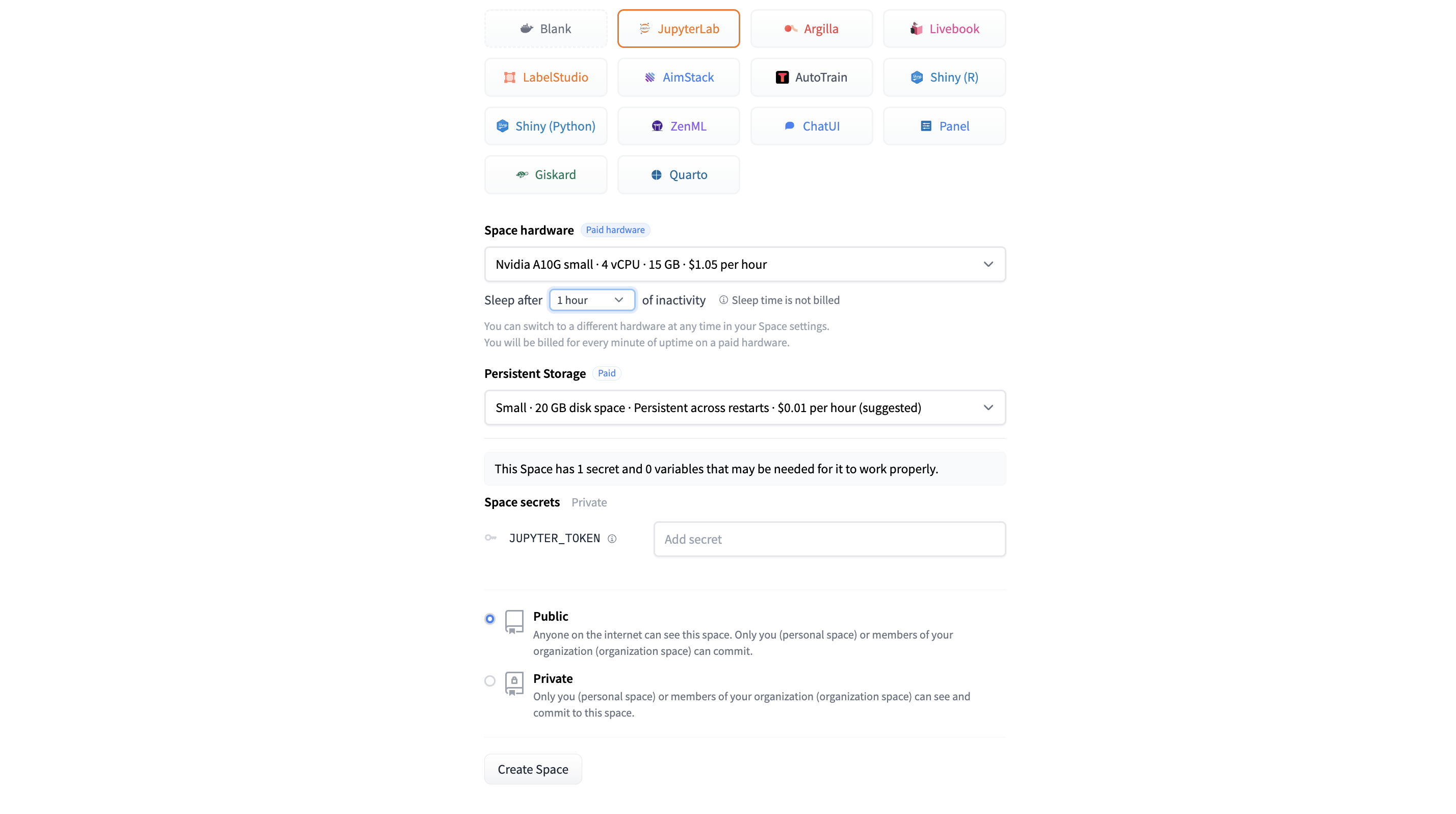
为什么我需要选择 Space 硬件选为 GPU?
默认情况下,我们为 Space 配备了免费的 CPU,这对于某些应用来说足够了。然而,LLM 中的许多计算能大大受益于并行加速,而这正是 GPU 所擅长的。
此外,在选择 GPU 时,选择足够的显存以利于存储模型并提供充足的备用工作内存也很重要。在我们的例子中,24GB 的 A10G Small 对于 Phi-2 来说够用了。
- 登录 JupyterLab
- 新建好空间后,你会看到登录页。如果你在模板中把令牌保留为默认值,则可以填入 “huggingface” 以登录。否则,只需使用你设置的令牌即可。
- 创建一个新 notebook
- 在
Launcher选项卡中,选择Notebook一栏下的Python 3图标,以创建一个安装了 Python 的新 notebook 环境
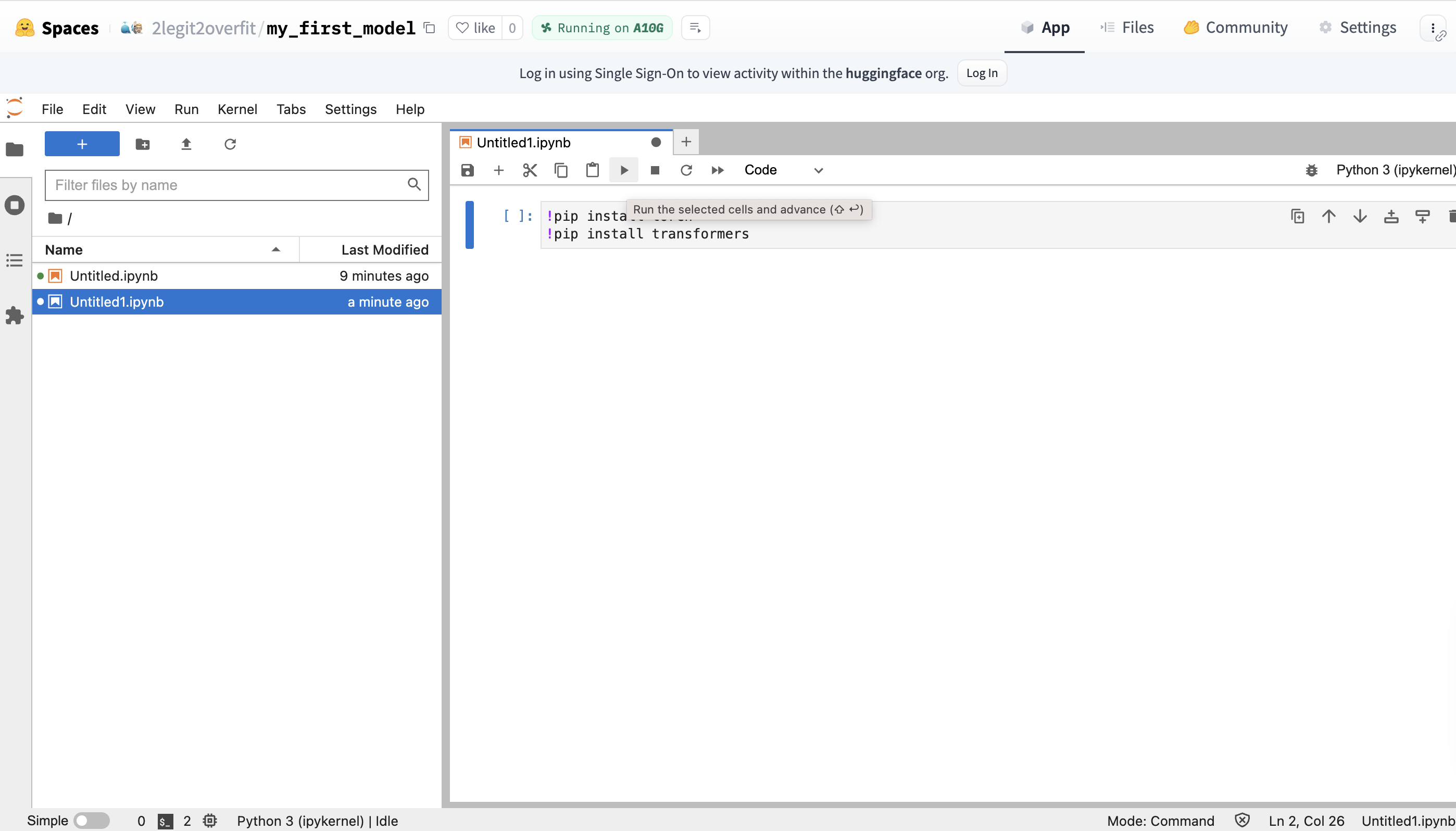
- 安装所需包
-
在新 notebook 中,安装 PyTorch 和 transformers 库,因为其并未预装在环境中。
-
你可以通过在 notebook 中输入 !pip 命令 + 库名来安装。单击播放按钮以执行代码你可以看到库的安装过程 (也可同时按住 CMD + Return / CTRL + Enter 键)
!pip install torch
!pip install transformers!pip install 是什么?
!pip 是一个从 Python 包仓库中 (PyPI) 安装 Python 包的命令,Python 包仓库是一个可在 Python 环境中使用的库的 Web 存储库。它使得我们可以引入各种第三方附加组件以扩展 Python 应用程序的功能。
既然我们用了 transformers,为什么还需要 PyTorch?
Hugging Face 是一个构建在 PyTorch、TensorFlow 和 JAX 等框架之上的上层库。在本例中,我们使用的是基于 PyTorch 的 transformers 库,因此需要安装 PyTorch 才能使用其功能。
- 从 transformers 中导入 AutoTokenizer 和 AutoModelForCausalLM 类
- 另起一行,输入以下代码并运行
from transformers import AutoTokenizer, AutoModelForCausalLM类是什么?
你可将类视为可用于创建对象的代码配方。类很有用,因为其允许我们使用属性和函数的组合来保存对象。这反过来又简化了编码,因为特定对象所需的所有信息和操作都可以从同一处访问。我们会使用 transformers 提供的类来创建两个对象: 一个是 model ,另一个是 tokenizer 。
为什么安装 transformers 后需要再次导入所需类?
尽管我们已安装 transformers,但其中的特定类并不会自动在你的环境中使能。Python 要求我们显式导入各类,这样做有助于避免命名冲突并确保仅将库的必要部分加载到当前工作上下文中。
- 定义待运行的模型
- 想要指明需从 Hugging Face Hub 下载和运行哪个模型,你需要在代码中指定模型存储库的名称。
- 我们通过设置一个表明模型名称的变量来达成这一点,本例我们使用的是
model_id变量。 - 我们选用 Microsoft 的 Phi-2 模型,这个模型虽小但功能惊人,用户可以在 https://huggingface.co/microsoft/phi-2 上找到它。注意: Phi-2 是一个基础模型,而不是指令微调模型,因此如果你想将它用于聊天,其响应会比较奇怪。
model_id = "microsoft/phi-2"什么是指令微调模型?
指令微调语言模型一般是通过对其基础版本进一步训练而得,通过该训练过程,我们希望其能学会理解和响应用户给出的命令或提示,从而提高其遵循指令的能力。基础模型能够自动补全文本,但通常响应命令的能力较弱。稍后我们使用 Phi 时,会看到这一点。
- 创建模型对象并加载模型
- 要将模型从 Hugging Face Hub 加载到本地,我们需要实例化模型对象。我们通过将上一步中定义的
model_id作为参数传递给AutoModelForCausalLM类的.from_pretrained来达到此目的。 - 运行代码并喝口水,模型可能需要几分钟才能下载完毕。
model = AutoModelForCausalLM.from_pretrained(model_id)参数是什么?
参数是传递给函数以便其计算输出的信息。我们通过将参数放在函数括号之间来将参数传递给函数。本例中,模型 ID 是唯一的参数。但其实,函数可以有多个参数,也可以没有参数。
方法是什么?
方法是函数的另一个名称,其与一般函数的区别在于其可使用本对象或类的信息。本例中, .from_pretrained 方法使用本类以及 model_id 的信息创建了新的 model 对象。
- 创建分词器对象并加载分词器
- 要加载分词器,你需要创建一个分词器对象。要执行此操作,需再次将
model_id作为参数传递给AutoTokenizer类的.from_pretrained方法。 - 请注意,本例中还使用了其他一些参数,但当前而言,理解它们并不重要,因此我们不会解释它们。
tokenizer = AutoTokenizer.from_pretrained(model_id, add_eos_token=True, padding_side='left')分词器是什么?
分词器负责将句子分割成更小的文本片段 (词元) 并为每个词元分配一个称为输入 id 的值。这么做是必需的,因为我们的模型只能理解数字,所以我们首先必须将文本转换 (也称为编码) 为模型可以理解的形式。每个模型都有自己的分词器词表,因此使用与模型训练时相同的分词器很重要,否则它会误解文本。
- 为模型创建输入
- 定义一个新变量
input_text,用于接受输入给模型的提示文本。本例中,我们使用的是“Who are you?”, 但你完全可以选择自己喜欢的任何内容。 - 将新变量作为参数传递给分词器对象以创建
input_ids - 将传给
tokenizer对象的第二个参数设为return_tensors="pt",这会确保token_id表示为我们正在使用的底层框架所需的正确格式的向量 (即 PyTorch 所需的格式而不是 TensorFlow 所需的)。
input_text = "Who are you?"
input_ids = tokenizer(input_text, return_tensors="pt")- 生成文本并对输出进行解码
- 现在,我们需要将正确格式的输入传给模型,我们通过对
model对象调用.generate方法来执行此操作,将input_ids作为参数传给.generate方法并将其输出赋给outputs变量。我们还将第二个参数max_new_tokens设为 100,这限制了模型需生成的词元数。 - 此时,输出还不是人类可读的,为了将它们转换至文本,我们必须对输出进行解码。我们可以使用
.decode方法来完成此操作,并将其保存到变量decoded_outputs中。 - 最后,将
decoded_output变量传递给print函数以利于我们在 notebook 中查看模型输出。 - 可选: 将
outputs变量传递给print函数,以比较其与decoded_output的异同。
outputs = model.generate(input_ids["input_ids"], max_new_tokens=100)
decoded_outputs = tokenizer.decode(outputs[0])
print(decoded_outputs)为什么需要解码?
模型只理解数字,因此当我们提供 input_ids 作为输入时,它会返回相同格式的输出。为了将这些输出转换为文本,我们需要反转之前使用分词器所做的编码操作。
为什么输出读起来像一个故事?
还记得之前说的吗?Phi-2 是一个基础模型,尚未针对对话场景进行指令微调,因此它实际上是一个大型自动补全模型。根据你的输入,它会根据之前见过的所有网页、书籍以及其他内容来预测它认为接下来最有可能出现的内容。
恭喜,你已经完成了你的第一个 LLM 推理之旅!
希望通过这个例子可以帮助大家更好地了解开源机器学习世界。如果你想继续你的 ML 学习之旅,推荐大家试试我们最近与 DeepLearning AI 合作推出的这个 Hugging Face 课程。
赞赏英文原文: https://hf.co/blog/noob_intro_transformers
原文作者: Andrew Jardine
译者: Matrix Yao (姚伟峰),英特尔深度学习工程师,工作方向为 transformer-family 模型在各模态数据上的应用及大规模模型的训练推理。
 微信赞赏
微信赞赏 支付宝赞赏
支付宝赞赏
相关文章

