4## 引言
基于 transformer 的模型已被证明对很多 NLP 任务都非常有用。然而,$$O(n^2)$$ 的时间和内存复杂度 (其中 $$n$$ 是序列长度) 使得在长序列 ($n > 512$$) 上应用它们变得非常昂贵,因而大大限制了其应用。最近的几篇论文,如 Longformer 、Performer 、Reformer 、簇状注意力 都试图通过对完整注意力矩阵进行近似来解决这个问题。如果你不熟悉这些模型,可以查看 🤗 之前的 博文。
BigBird (由 该论文 引入) 是解决这个问题的最新模型之一。 BigBird 依赖于 块稀疏注意力 而不是普通注意力 ( 即 BERT 的注意力),与 BERT 相比,这一新算法能以低得多的计算成本处理长达 4096 的序列。在涉及很长序列的各种任务上,该模型都实现了 SOTA,例如长文档摘要、长上下文问答。
RoBERTa 架构的 BigBird 模型现已集成入 🤗 transformers 中。本文的目的是让读者 深入 了解 BigBird 的实现,并让读者能在 🤗 transformers 中轻松使用 BigBird。但是,在更深入之前,一定记住 BigBird 注意力只是 BERT 完全注意力的一个近似,因此我们并不纠结于让它比 BERT 完全注意力 更好,而是致力于让它更有效率。有了它,transformer 模型就可以作用于更长的序列,因为 BERT 的二次方内存需求很快会变得难以为继。简而言之,如果我们有 $$\infty$$ 计算和 $$\infty$$ 时间,那么用 BERT 注意力就好了,完全没必要用本文讨论的块稀疏注意力。
如果你想知道为什么在处理较长序列时需要更多计算,那么本文正合你意!
在使用标准的 BERT 类注意力时可能会遇到以下几个主要问题:
- 每个词元真的都必须关注所有其他词元吗?
- 为什么不只计算重要词元的注意力?
- 如何决定哪些词元重要?
- 如何以高效的方式处理少量词元?
本文,我们将尝试回答这些问题。
应该关注哪些词元?
下面,我们将以句子 BigBird is now available in HuggingFace for extractive Question Answering 为例来说明注意力是如何工作的。在 BERT 这类的注意力机制中,每个词元都简单粗暴地关注所有其他词元。从数学上来讲,这意味着每个查询的词元 $$\text{query-token} \in {\text{BigBird},\text{is},\text{now},\text{available},\text{in},\text{HuggingFace},\text{for},\text{extractive},\text{question},\text{answering}}$$,
将关注每个键词元 $$\text{key-tokens} = \left[\text{BigBird},\text{is},\text{now},\text{available},\text{in},\text{HuggingFace},\text{for},\text{extractive},\text{question},\text{answering} \right]$$。
我们考虑一下 每个查询词元应如何明智地选择它实际上应该关注的键词元 这个问题,下面我们通过编写伪代码的方式来整理思考过程。
假设 available 是当前查询词元,我们来构建一个合理的、需要关注的键词元列表。
# 以下面的句子为例
example = ['BigBird', 'is', 'now', 'available', 'in', 'HuggingFace', 'for', 'extractive', 'question', 'answering']
# 假设当前需要计算 'available' 这个词的表征
query_token = 'available'
# 初始化一个空集合,用于放 'available' 这个词的键词元
key_tokens = [] # => 目前,'available' 词元不关注任何词元邻近词元当然很重要,因为在一个句子 (单词序列) 中,当前词高度依赖于前后的邻近词。滑动注意力 即基于该直觉。
# 考虑滑动窗大小为 3, 即将 'available' 的左边一个词和右边一个词纳入考量
# 左词: 'now'; 右词: 'in'
sliding_tokens = ["now", "available", "in"]
# 用以上词元更新集合
key_tokens.append(sliding_tokens)长程依赖关系: 对某些任务而言,捕获词元间的长程关系至关重要。 例如 ,在问答类任务中,模型需要将上下文的每个词元与整个问题进行比较,以便能够找出上下文的哪一部分对正确答案有用。如果大多数上下文词元仅关注其他上下文词元,而不关注问题,那么模型从不太重要的上下文词元中过滤重要的上下文词元就会变得更加困难。
BigBird 提出了两种允许长程注意力依赖的方法,这两种方法都能保证计算效率。
- 全局词元: 引入一些词元,这些词元将关注每个词元并且被每个词元关注。例如,对 “HuggingFace is building nice libraries for easy NLP” ,现在假设 ‘building’ 被定义为全局词元,而对某些任务而言,模型需要知道 ‘NLP’ 和 ‘HuggingFace’ 之间的关系 (注意: 这 2 个词元位于句子的两端); 现在让 ‘building’ 在全局范围内关注所有其他词元,会对模型将 ‘NLP’ 与 ‘HuggingFace’ 关联起来有帮助。
# 我们假设第一个和最后一个词元是全局的,则有:
global_tokens = ["BigBird", "answering"]
# 将全局词元加入到集合中
key_tokens.append(global_tokens)- 随机词元: 随机选择一些词元,这些词元将通过关注其他词元来传输信息,而那些词元又可以传输信息到其他词元。这可以降低直接从一个词元到另一个词元的信息传输成本。
# 现在,我们可以从句子中随机选择 `r` 个词元。这里,假设 `r` 为 1, 选择了 `is` 这个词元
>>> random_tokens = ["is"] # 注意: 这个是完全随机选择的,因此可以是任意词元。
# 将随机词元加入到集合中
key_tokens.append(random_tokens)
# 现在看下 `key_tokens` 集合中有哪些词元
key_tokens
{'now', 'is', 'in', 'answering', 'available', 'BigBird'}
# 至此,查询词 'available' 仅关注集合中的这些词元,而不用关心全部这样,查询词元仅关注所有词元的一个子集,该子集能够产生完全注意力值的一个不错的近似。相同的方法将用于所有其他查询词元。但请记住,这里的重点是尽可能有效地接近 BERT 的完全注意力。BERT 那种简单地让每个查询词元关注所有键词元的做法可以建模为一系列矩阵乘法,从而在现代硬件 (如 GPU) 上进行高效计算。然而,滑动、全局和随机注意力的组合似乎意味着稀疏矩阵乘法,这在现代硬件上很难高效实现。BigBird 的主要贡献之一是提出了 块稀疏 注意力机制,该机制可以高效计算滑动、全局和随机注意力。我们来看看吧!
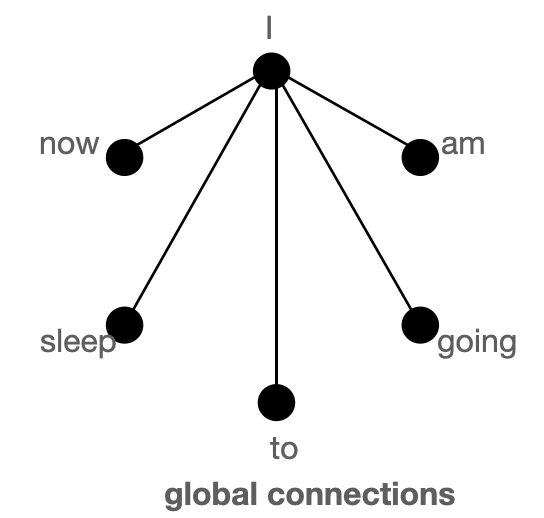
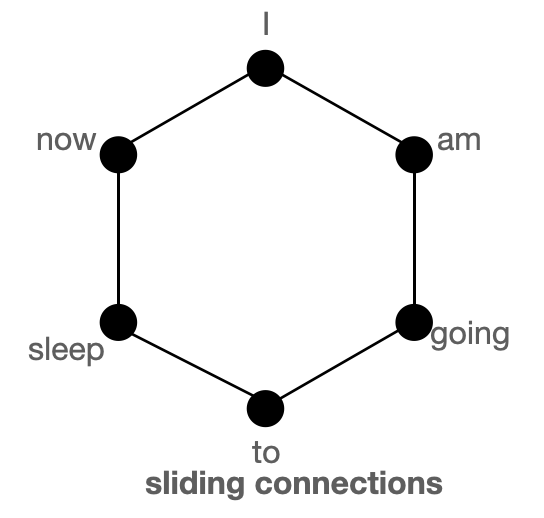
图解全局、滑动、随机注意力的概念
首先,我们借助图来帮助理解“全局”、“滑动”和“随机”注意力,并尝试理解这三种注意力机制的组合是如何较好地近似标准 BERT 类注意力的。
 |
 |
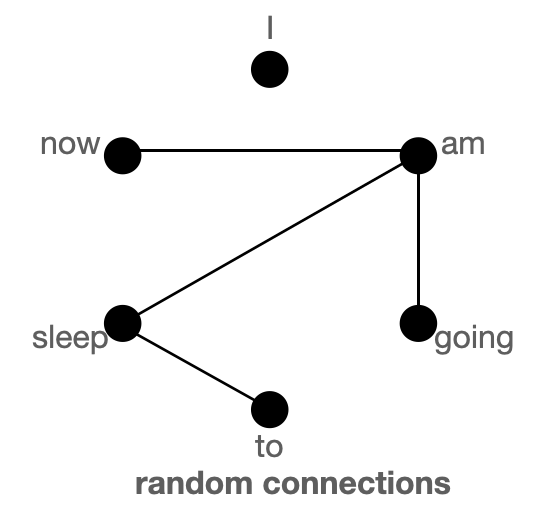 |
上图分别把“全局”(左) 、“滑动”(中) 和“随机”(右) 连接建模成一个图。每个节点对应一个词元,每条边代表一个注意力分数。如果 2 个词元之间没有边连接,则其注意力分数为 0。
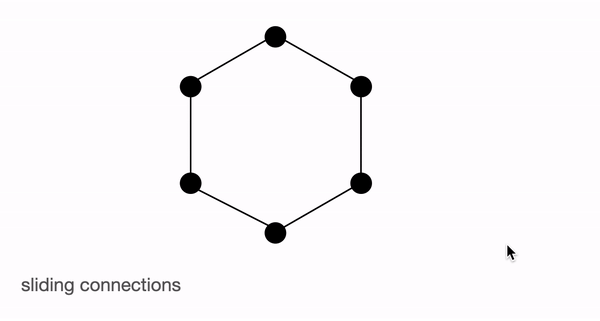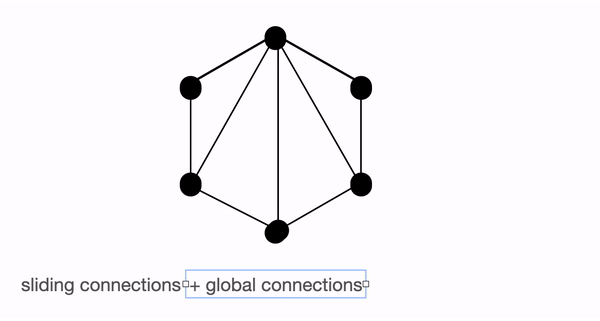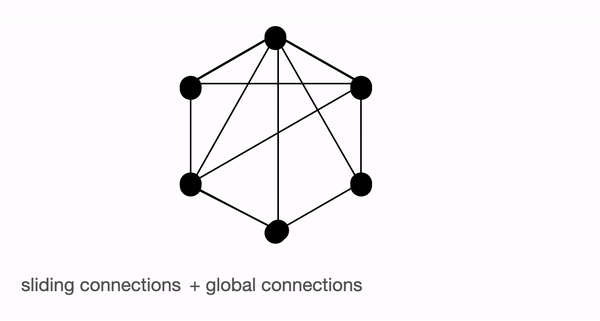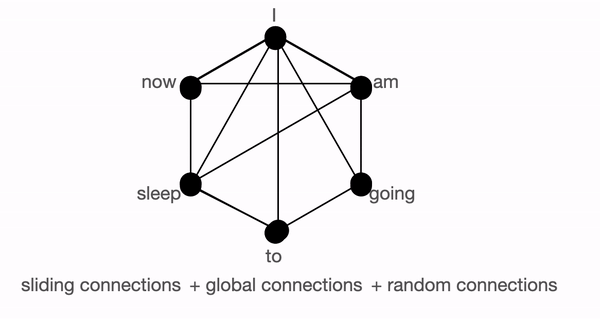
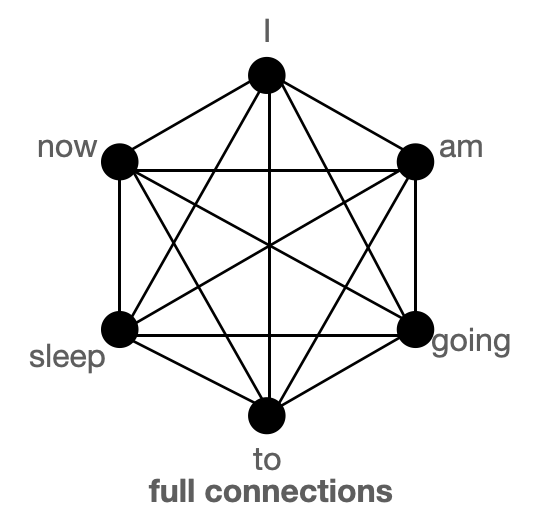
BigBird 块稀疏注意力 是滑动连接、全局连接和随机连接 (总共 10 个连接) 的组合,如上图左侧动图所示。而 完全注意力 图 (右侧) 则是有全部 15 个连接 (注意: 总共有 6 个节点)。你可以简单地将完全注意力视为所有词元都是全局词元 $${}^1$$。
完全注意力: 模型可以直接在单个层中将信息从一个词元传输到另一个词元,因为每个词元都会对每个其他词元进行查询,并且受到其他每个词元的关注。我们考虑一个与上图类似的例子,如果模型需要将 ‘going’ 与 ‘now’ 关联起来,它可以简单地在单层中执行此操作,因为它们两个是有直接连接的。
块稀疏注意力: 如果模型需要在两个节点 (或词元) 之间共享信息,则对于某些词元,信息将必须经过路径中的各个其他节点; 因为不是所有节点都有直接连接的。
例如 ,假设模型需要将 going 与 now 关联起来,那么如果仅存在滑动注意力,则这两个词元之间的信息流由路径 going -> am -> i -> now 来定义,也就是说它必须经过 2 个其他词元。因此,我们可能需要多个层来捕获序列的全部信息,而正常的注意力可以在单层中捕捉到这一点。在极端情况下,这可能意味着需要与输入词元一样多的层。然而,如果我们引入一些全局词元,信息可以通过以下路径传播 going -> i -> now ,这可以帮助缩短路径。如果我们再另外引入随机连接,它就可以通过 going -> am -> now 传播。借助随机连接和全局连接,信息可以非常快速地 (只需几层) 从一个词元传输到下一个词元。
如果我们有很多全局词元,那么我们可能不需要随机连接,因为信息可以通过多个短路径传播。这就是在使用 BigBird 的变体 (称为 ETC) 时设置 num_random_tokens = 0 的动机 (稍后部分将会详细介绍)。
$${}^1$$ 在这些图中,我们假设注意力矩阵是对称的 即 $$\mathbf{A} {ij} = \mathbf{A} {ji}$$ 因为在图中如果某个词元 A 关注 B,那么 B 也会关注 A。从下一节所示的注意力矩阵图中可以看出,这个假设对于 BigBird 中的大多数词元都成立。
| 注意力类型 | 全局次元 | 滑动词元 | 随机词元 |
|---|---|---|---|
| 原始完全注意力 | n |
0 | 0 |
| 块稀疏注意力 | 2 x block_size |
3 x block_size |
num_random_blocks x block_size |
原始完全注意力即 BERT 的注意力,而块稀疏注意力则是 BigBird 的注意力。想知道 block_size 是什么?请继续阅读下文。现在,为简单起见,将其视为 1。
BigBird 块稀疏注意力
BigBird 块稀疏注意力是我们上文讨论的内容的高效实现。每个词元都关注某些 全局词元 、 滑动词元 和 随机词元,而不管其他 所有 词元。作者分别实现了每类查询注意力矩阵,并使用了一个很酷的技巧来加速 GPU 和 TPU 上的训练/推理。
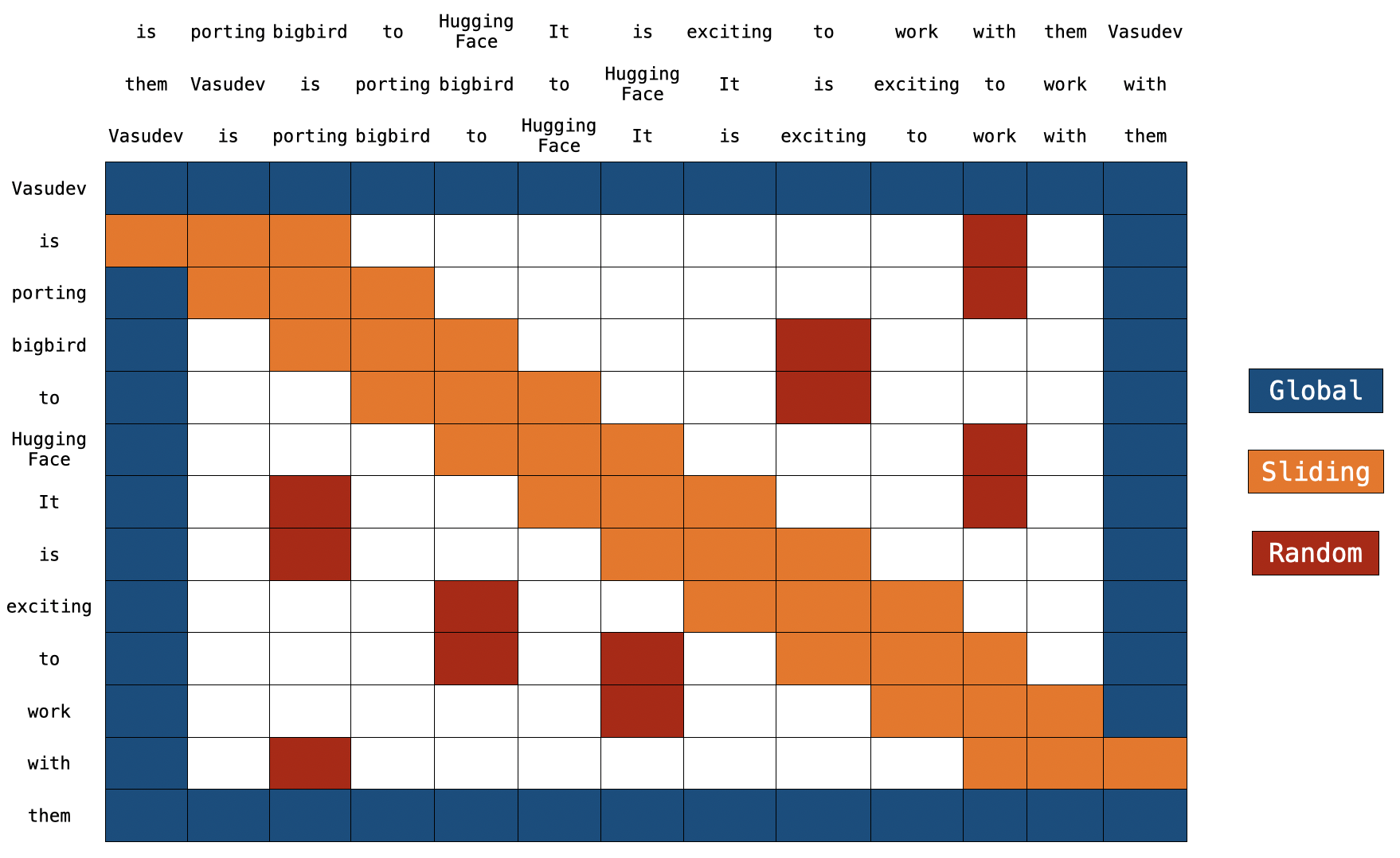
_注意: 在上图的顶部有 2 个额外的句子。正如你所注意到的,两个句子中的每个词元都只是交换了一个位置。这就是滑动注意力的实现方式。当 q[i] 与 k[i,0:3] 相乘时,我们会得到 q[i] 的滑动注意力分数 (其中MARKDOWN_HASH865c0c0b4ab0e063e5caa3387c1a8741MARKDOWNHASH 是序列中元素的索引)。
你可以在 这儿 找到 block_sparse 注意力的具体实现。现在看起来可能非常可怕😨😨,但这篇文章肯定会让你轻松理解它。
全局注意力
对于全局注意力而言,每个查询词元关注序列中的所有其他词元,并且被其他每个词元关注。我们假设 Vasudev (第一个词元) 和 them (最后一个词元) 是全局的 (如上图所示)。你可以看到这些词元直接连接到所有其他词元 (蓝色框)。
# 伪代码
Q -> Query martix (seq_length, head_dim)
K -> Key matrix (seq_length, head_dim)
# 第一个和最后一个词元关注所有其他词元
Q[0] x [K[0], K[1], K[2], ......, K[n-1]]
Q[n-1] x [K[0], K[1], K[2], ......, K[n-1]]
# 第一个和最后一个词元也被其他所有词元关注
K[0] x [Q[0], Q[1], Q[2], ......, Q[n-1]]
K[n-1] x [Q[0], Q[1], Q[2], ......, Q[n-1]]滑动注意力
键词元序列被复制两次,其中一份每个词元向右移动一步,另一份每个词元向左移动一步。现在,如果我们将查询序列向量乘以这 3 个序列向量,我们将覆盖所有滑动词元。计算复杂度就是 O(3n) = O(n) 。参考上图,橙色框代表滑动注意力。你可以在图的顶部看到 3 个序列,其中 2 个序列各移动了一个词元 (1 个向左,1 个向右)。
# 我们想做的
Q[i] x [K[i-1], K[i], K[i+1]] for i = 1:-1
# 高效的代码实现 (👇 乘法为点乘)
[Q[0], Q[1], Q[2], ......, Q[n-2], Q[n-1]] x [K[1], K[2], K[3], ......, K[n-1], K[0]]
[Q[0], Q[1], Q[2], ......, Q[n-1]] x [K[n-1], K[0], K[1], ......, K[n-2]]
[Q[0], Q[1], Q[2], ......, Q[n-1]] x [K[0], K[1], K[2], ......, K[n-1]]
# 每个序列被乘 3 词, 即 `window_size = 3`。为示意,仅列出主要计算,省略了一些计算。随机注意力
随机注意力确保每个查询词元也会关注一些随机词元。对实现而言,这意味着模型随机选取一些词元并计算它们的注意力分数。
# r1, r2, r 为随机索引; 注意 r1, r2, r 每行取值不同 👇
Q[1] x [Q[r1], Q[r2], ......, Q[r]]
.
.
.
Q[n-2] x [Q[r1], Q[r2], ......, Q[r]]
# 不用管第 0 个和第 n-1 个词元,因为它们已经是全局词元了。注意: 当前的实现进一步将序列划分为块,并且每个符号都依块而定义而非依词元而定义。我们在下一节中会更详细地讨论这个问题。
实现
回顾: 在常规 BERT 注意力中,一系列词元,即 $$X = x_1, x_2, …., x_n$$ 通过线性层投影到 $$Q,K,V$$,并基于它们计算注意力分数 $$Z$$,公式为 $$Z=Softmax(QK^T)$$。使用 BigBird 块稀疏注意力时,我们使用相同的算法,但仅针对一些选定的查询和键向量进行计算。
我们来看看 BigBird 块稀疏注意力是如何实现的。首先,我们用 $$b、r、s、g$$ 分别代表 block_size 、num_random_blocks 、num_sliding_blocks 、num_global_blocks 。我们以 $$b=4,r=1,g=2,s=3,d=5$$ 为例来说明 BigBird 块稀疏注意力的机制部分,如下所示:
$${q} {1}、{q} {2}、{q} {3:n-2}、{q} {n-1}、{q}_{n}$$ 的注意力分数分别计算如下:
$\mathbf{q}_{1}$$ 的注意力分数由 $$a_1$$ 表示,其中 $$a_1=Softmax(q_1 * K^T)$$,即为第一块中的所有词元与序列中的所有其他词元之间的注意力分数。

$$q_1$$ 表示第 1 块,$$g_i$$ 表示第 $$i$$ 块。我们仅在 $$q_1$$ 和 $$g$$ (即所有键) 之间执行正常的注意力操作。
为了计算第二块中词元的注意力分数,我们收集前三块、最后一块和第五块。然后我们可以计算 $$a_2 = Softmax(q_2 * concat(k_1, k_2, k_3, k_5, k_7))$$。
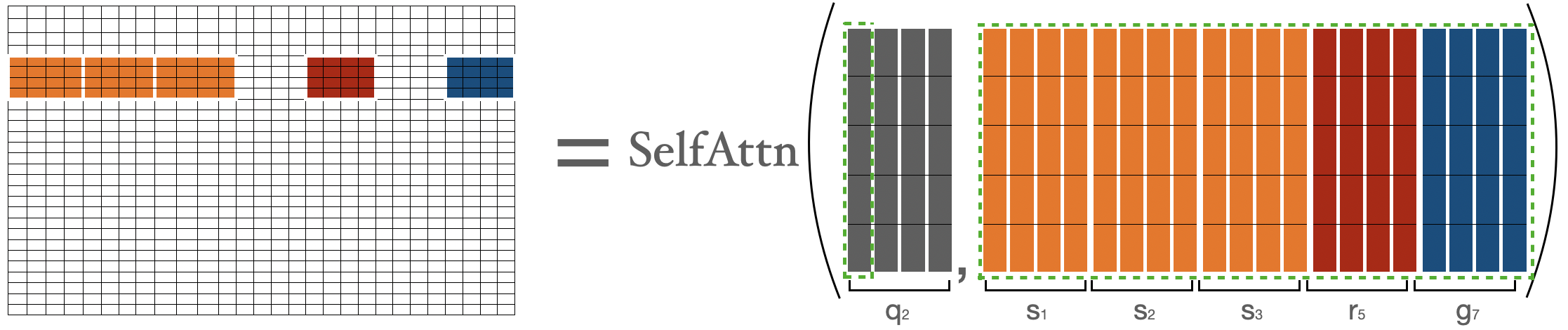
这里,我用 $$g,r,s$$ 表示词元只是为了明确地表示它们的性质 (即是全局、随机还是滑动词元),只用 $$k$$ 无法表示他们各自的性质。
为了计算 $${q} {3:n-2}$$ 的注意力分数,我们先收集相应的全局、滑动、随机键向量,并基于它们正常计算 $${q} {3:n-2}$$ 上的注意力。请注意,正如前面滑动注意力部分所讨论的,滑动键是使用特殊的移位技巧来收集的。

为了计算倒数第二块 (即 $${q} {n-1}$$) 中词元的注意力分数,我们收集第一块、最后三块和第三块的键向量。然后我们用公式 $${a} {n-1} = Softmax({q}_{n-1} * concat(k_1, k_3, k_5, k_6, k_7))$$ 进行计算。这和计算 $$q_2$$ 非常相似。
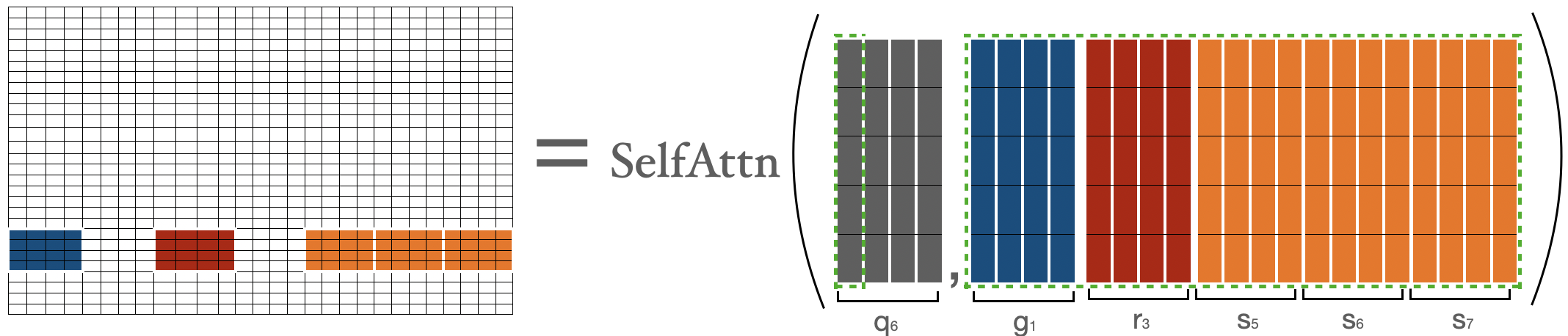
最后一块 $$\mathbf{q}_{n}$$ 的注意力分数由 $$a_n$$ 表示,其中 $$a_n=Softmax(q_n * K^T)$$,只不过是最后一块中的所有词元与序列中的所有其他词元之间的注意力分数。这与我们对 $$q_1$$ 所做的非常相似。

我们将上面的矩阵组合起来得到最终的注意力矩阵。该注意力矩阵可用于获取所有词元的表征。
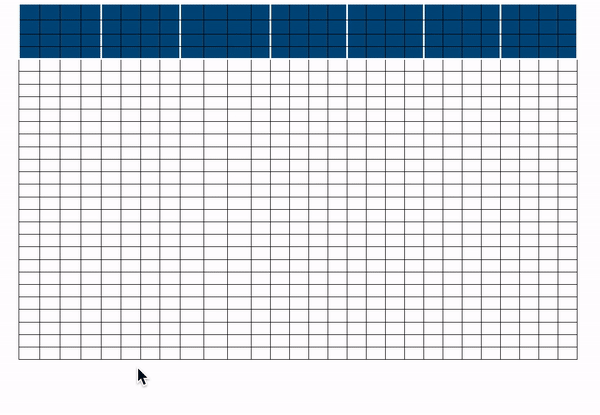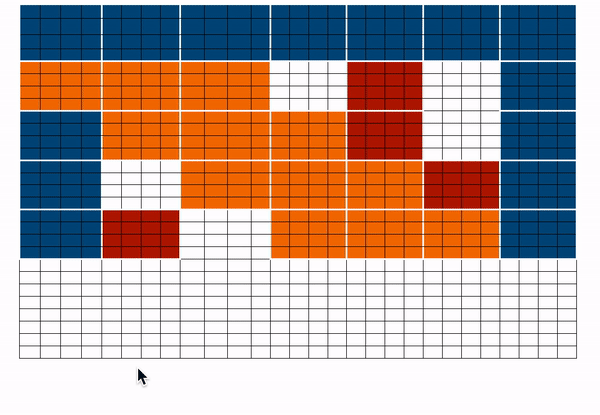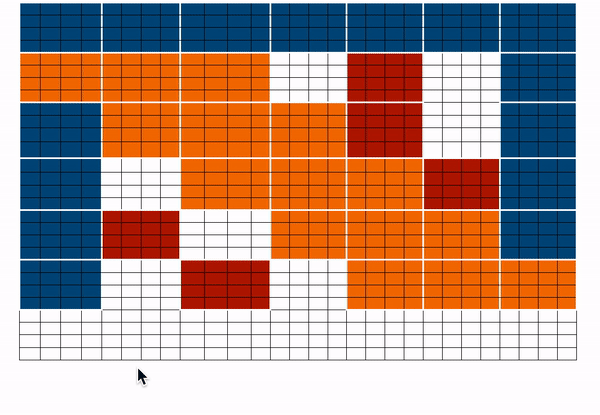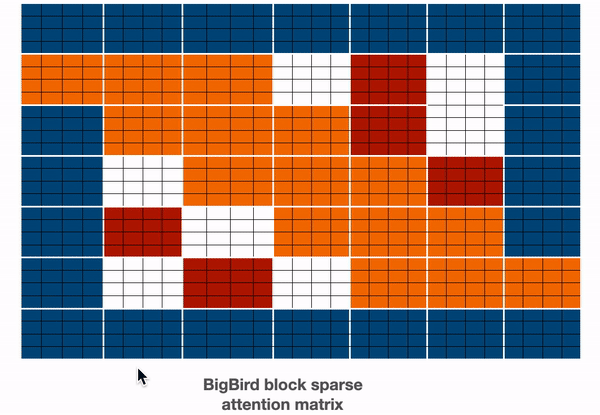
_上图中 蓝色 -> 全局块 、红色 -> 随机块 、MARKDOWN_HASHb0721527ad0a219fd72d4920f8cce18aMARKDOWNHASH 。在前向传播过程中,我们不存储“白色”块,而是直接为每个单独的部分计算加权值矩阵 (即每个词元的表示),如上所述。
现在,我们已经介绍了块稀疏注意力最难的部分,即它的实现。希望对你更好地理解实际代码有帮助。现在你可以深入研究代码了,在此过程中你可以将代码的每个部分与上面的某个部分联系起来以助于理解。
时间和内存复杂度
| 注意力类型 | 序列长度 | 时间和内存复杂度 |
|---|---|---|
| 原始完全注意力 | 512 | T |
| 1024 | 4 x T |
|
| 4096 | 64 x T |
|
| 块稀疏注意力 | 1024 | 2 x T |
| 4096 | 8 x T |
BERT 注意力和 BigBird 块稀疏注意力的时间和空间复杂度之比较。
展开以了解复杂度的计算过程。
“`md
BigBird 时间复杂度 = O(w x n + r x n + g x n)
BERT 时间复杂度 = O(n^2)
假设:
w = 3 x 64
r = 3 x 64
g = 2 x 64
当序列长度为 512 时
=> **BERT 时间复杂度 = 512^2**
当序列长度为 1024 时
=> BERT 时间复杂度 = (2 x 512)^2
=> **BERT 时间复杂度 = 4 x 512^2**
=> BigBird 时间复杂度 = (8 x 64) x (2 x 512)
=> **BigBird 时间复杂度 = 2 x 512^2**
当序列长度为 4096 时
=> BERT 时间复杂度 = (8 x 512)^2
=> **BERT 时间复杂度 = 64 x 512^2**
=> BigBird 时间复杂度 = (8 x 64) x (8 x 512)
=> BigBird 时间复杂度 = 8 x (512 x 512)
=> **BigBird 时间复杂度 = 8 x 512^2**
“`
ITC 与 ETC
BigBird 模型可以使用 2 种不同的策略进行训练: ITC 和 ETC。 ITC (internal transformer construction,内部 transformer 构建) 就是我们上面讨论的。在 ETC (extended transformer construction,扩展 transformer 构建) 中,会有更多的全局词元,以便它们关注所有词元或者被所有词元关注。
ITC 需要的计算量较小,因为很少有词元是全局的,同时模型可以捕获足够的全局信息 (也可以借助随机注意力)。而 ETC 对于需要大量全局词元的任务非常有帮助,例如对 问答 类任务而言,整个问题应该被所有上下文关注,以便能够将上下文正确地与问题相关联。
注意: BigBird 论文显示,在很多 ETC 实验中,随机块的数量设置为 0。考虑到我们上文图解部分的讨论,这是合理的。
下表总结了 ITC 和 ETC:
| ITC | ETC | |
|---|---|---|
| 全局注意力的注意力矩阵 | ( A = \begin{bmatrix} 1 & 1 & 1 & 1 & 1 & 1 & 1 \ 1 & & & & & & 1 \ 1 & & & & & & 1 \ 1 & & & & & & 1 \ 1 & & & & & & 1 \ 1 & & & & & & 1 \ 1 & 1 & 1 & 1 & 1 & 1 & 1 \end{bmatrix} ) | ( B = \begin{bmatrix} 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 \ 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 \ 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 \ 1 & 1 & 1 & & & & & & 1 \ 1 & 1 & 1 & & & & & & 1 \ 1 & 1 & 1 & & & & & & 1 \ 1 & 1 & 1 & & & & & & 1 \ 1 & 1 & 1 & & & & & & 1 \ 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 \end{bmatrix} ) |
| 全局词元 | 2 x block_size |
extra_tokens + 2 x block_size |
| 随机词元 | num_random_blocks x block_size |
num_random_blocks x block_size |
| 滑动词元 | 3 x block_size |
3 x block_size |
在 🤗Transformers 中使用 BigBird
你可以像使用任何其他 🤗 模型一样使用 BigBirdModel 。我们看一下代码:
from transformers import BigBirdModel
# 从预训练 checkpoint 中加载 bigbird 模型
model = BigBirdModel.from_pretrained("google/bigbird-roberta-base")
# 使用默认配置初始化模型,如 attention_type = "block_sparse",num_random_blocks = 3,block_size = 64
# 你也可以按照自己的需要改变这些参数。这 3 个参数只改变每个查询词元关注的词元数。
model = BigBirdModel.from_pretrained("google/bigbird-roberta-base", num_random_blocks=2, block_size=16)
# 通过把 attention_type 设成 `original_full`,BigBird 就会用复杂度为 n^2 的完全注意力。此时,BigBird 与 BERT 相似度为 99.9%。
model = BigBirdModel.from_pretrained("google/bigbird-roberta-base", attention_type="original_full")截至现在, 🤗 Hub 中总共有 3 个 BigBird checkpoint: bigbird-roberta-base,bigbird-roberta-large 以及 bigbird-base-trivia-itc。前两个检查点是使用 masked_lm 损失 预训练 BigBirdForPretraining 而得; 而最后一个是在 trivia-qa 数据集上微调 BigBirdForQuestionAnswering 而得。
让我们看一下如果用你自己喜欢的 PyTorch 训练器,最少需要多少代码就可以使用 🤗 的 BigBird 模型来微调你自己的任务。
# 以问答任务为例
from transformers import BigBirdForQuestionAnswering, BigBirdTokenizer
import torch
device = torch.device("cpu")
if torch.cuda.is_available():
device = torch.device("cuda")
# 我们用预训练权重初始化 bigbird 模型,并随机初始化其头分类器
model = BigBirdForQuestionAnswering.from_pretrained("google/bigbird-roberta-base", block_size=64, num_random_blocks=3)
tokenizer = BigBirdTokenizer.from_pretrained("google/bigbird-roberta-base")
model.to(device)
dataset = "torch.utils.data.DataLoader object"
optimizer = "torch.optim object"
epochs = ...
# 最简训练循环
for e in range(epochs):
for batch in dataset:
model.train()
batch = {k: batch[k].to(device) for k in batch}
# 前向
output = model(**batch)
# 后向
output["loss"].backward()
optimizer.step()
optimizer.zero_grad()
# 将最终权重存至本地目录
model.save_pretrained("<YOUR-WEIGHTS-DIR>")
# 将权重推到 🤗 Hub 中
from huggingface_hub import ModelHubMixin
ModelHubMixin.push_to_hub("<YOUR-WEIGHTS-DIR>", model_id="<YOUR-FINETUNED-ID>")
# 使用微调后的模型,以用于推理
question = ["How are you doing?", "How is life going?"]
context = ["<some big context having ans-1>", "<some big context having ans-2>"]
batch = tokenizer(question, context, return_tensors="pt")
batch = {k: batch[k].to(device) for k in batch}
model = BigBirdForQuestionAnswering.from_pretrained("<YOUR-FINETUNED-ID>")
model.to(device)
with torch.no_grad():
start_logits, end_logits = model(**batch).to_tuple()
# 这里,你可以使用自己的策略对 start_logits,end_logits 进行解码
# 注意:
# 该代码段仅用于展示即使你想用自己的 PyTorch 训练器微调 BigBrid,这也是相当容易的。
# 我会建议使用 🤗 Trainer,它更简单,功能也更多。使用 BigBird 时,需要记住以下几点:
- 序列长度必须是块大小的倍数,即
seqlen % block_size = 0。你不必担心,因为如果 batch 的序列长度不是block_size的倍数,🤗 transformers 会自动填充至最近的整数倍。 - 目前,Hugging Face 的实现 尚不支持 ETC,因此只有第一个和最后一个块是全局的。
- 当前实现不支持
num_random_blocks = 0。 - 论文作者建议当序列长度 < 1024 时设置
attention_type = "original_full"。 - 必须满足:
seq_length > global_token + random_tokens + moving_tokens + buffer_tokens,其中global_tokens = 2 x block_size、sliding_tokens = 3 x block_size、random_tokens = num_random_blocks x block_size且buffer_tokens = num_random_blocks x block_size。如果你不能满足这一点,🤗 transformers 会自动将attention_type切换为original_full并告警。 - 当使用 BigBird 作为解码器 (或使用
BigBirdForCasualLM) 时,attention_type应该是original_full。但你不用担心,🤗 transformers 会自动将attention_type切换为original_full,以防你忘记这样做。
下一步
@patrickvonplaten 建了一个非常酷的 笔记本,以展示如何在 trivia-qa 数据集上评估 BigBirdForQuestionAnswering 。你可以随意用这个笔记本来玩玩 BigBird。
BigBird 版的 Pegasus 模型很快就会面世,你可将它们用于 长文档摘要 💥。
尾注
你可在 此处 找到 块稀疏注意力矩阵 的原始实现。🤗 版的实现在 这儿。
赞赏英文原文: https://hf.co/blog/big-bird
原文作者: Vasudev Gupta
译者: Matrix Yao (姚伟峰),英特尔深度学习工程师,工作方向为 transformer-family 模型在各模态数据上的应用及大规模模型的训练推理。
 微信赞赏
微信赞赏 支付宝赞赏
支付宝赞赏
相关文章

