作者 / Google 开源安全团队 (GOSST): Mihai Maruseac、Sarah Meiklejohn、Mark Lodato
消费者和企业几乎每天都会接触到新的 AI 创新和应用。安全构建 AI 是至关重要的问题,我们相信 Google 的 安全 AI 框架 (SAIF) 可以为开发者指明方向,助力打造值得用户信赖的 AI 应用。在本文中,我们将重点介绍两种新的方式,让有关 AI 供应链安全的信息可被普遍发现和验证,从而以负责任的方式进行 AI 开发和使用。
SAIF 的首要原则是确保 AI 生态系统拥有坚实的安全基础。特别是,需要确保 AI 开发组件的软件供应链 (如机器学习模型) 免受威胁,如 模型篡改、数据中毒 和 有害内容 的产生。
即使机器学习和人工智能继续快速发展,现在仍有一些解决方案可供 ML 创作者使用。我们基于先前与 开源安全基金会 (OpenSSF) 合作的基础,向您展示 ML 模型创作者应该如何使用 SLSA 和 Sigstore 来保护 ML 供应链而免受攻击。
ML 供应链安全
对于传统软件 (不使用 ML 的软件) 的供应链安全,我们通常会考虑以下问题:
- 谁发布了软件?发布者值得信任吗?他们是否采取了安全做法?
- 对于开源软件,源代码是什么?
- 开发该软件用到了哪些依赖项?
- 软件 发布后是否可能被篡改版本替代?构建期间是否会发生这种情况?
所有这些问题也适用于互联网上可供使用的 数百种免费 ML 模型。使用 ML 模型意味着,就像信任其他软件一样信任模型的每个部分。其中包括以下问题:
- 谁发布了模型?发布者值得信任吗?他们是否采取了安全做法?
- 对于开源模型,训练代码是什么?
- 训练该模型用到了哪些数据集?
- 模型 发布后是否可能被篡改版本替代?训练期间是否会发生这种情况?
篡改 ML 模型和将恶意软件注入传统软件一样,属于严重程度的事件,我们应严肃处理。 事实上,由于 模型也属于程序,因而许多模型让攻击者能够利用相同类型的任意代码执行漏洞来攻击传统软件。此外,被篡改的模型可能会泄露或窃取数据、由于偏差造成伤害或传播危险的错误信息。
对 ML 模型进行检查并不足以确定是否被注入了不良行为。这类似于试图对可执行文件进行逆向工程以识别恶意软件。为了大规模保护供应链,我们需要了解如何开发模型或软件来解答上述问题。
ML 供应链安全解决方案
近年来,我们发现,针对软件开发不同阶段的情况提供公开、可验证的信息可以有效保护传统软件免受供应链攻击。这种供应链透明度通过以下方式提供保护和洞察:
供应链攻击将软件开发生命周期的每一步都变成恶意活动的潜在目标,而这些解决方案可以共同帮助应对 供应链攻击日益猖獗 的问题。
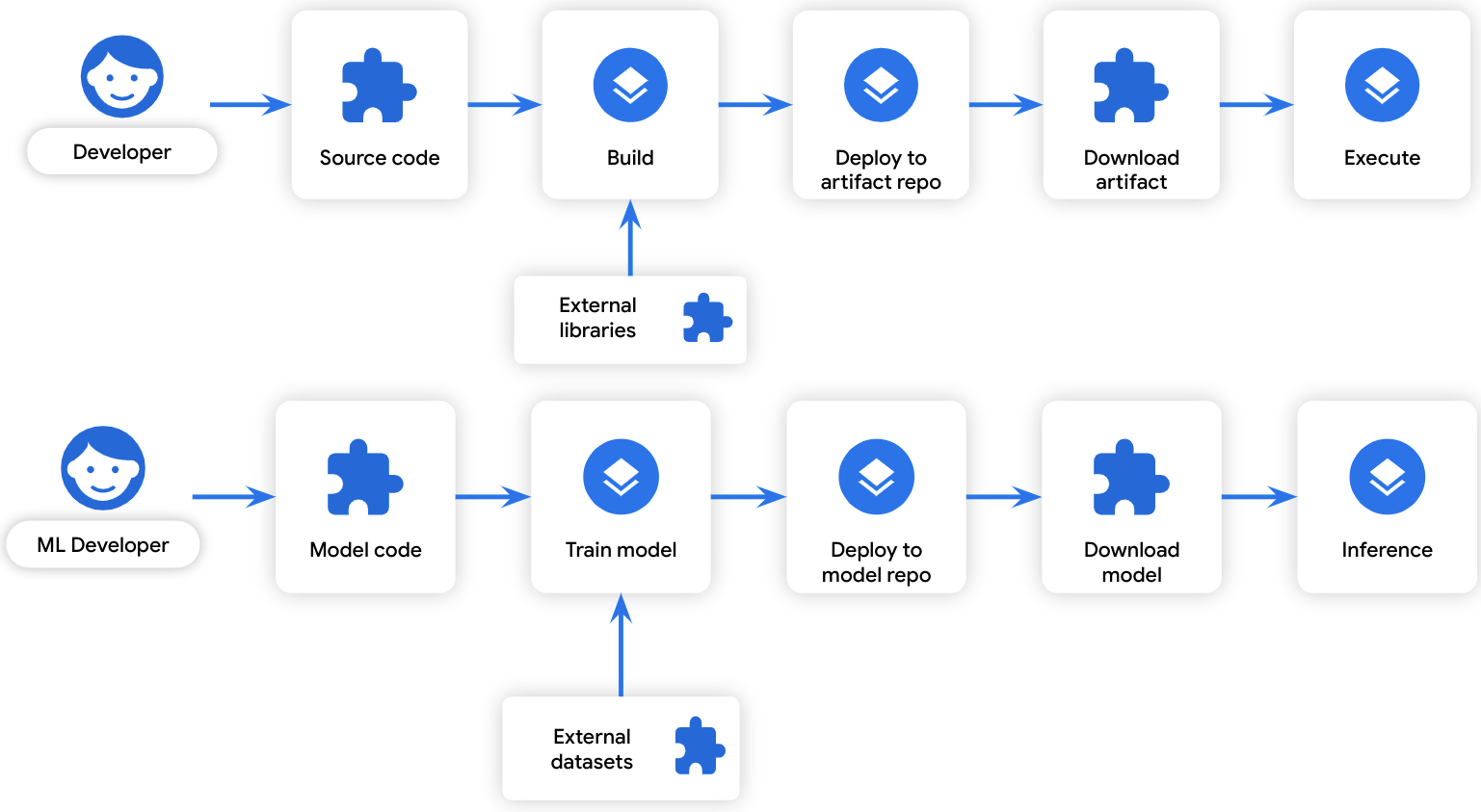
我们相信,在整个开发生命周期中保持透明度也将有助于保护 ML 模型,因为 ML 模型开发遵循着与常规软件工件开发 类似的生命周期:
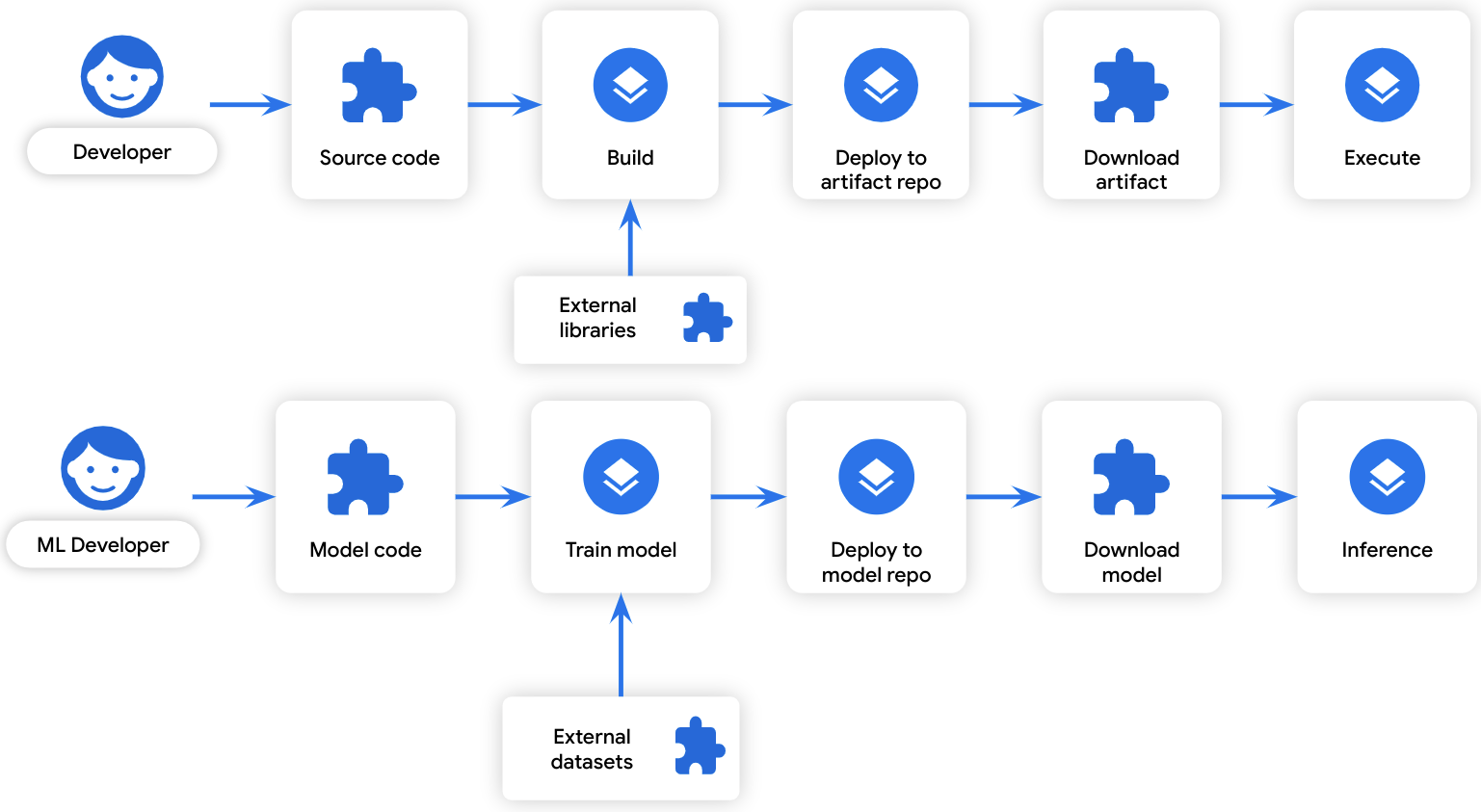
△ 软件开发与 ML 模型开发的相似之处
ML 训练过程可以被视为一种 "构建": 它将某些输入数据转换为输出数据。同样,训练数据可以被视为一种 "依赖项": 它是构建过程中使用的数据。由于开发生命周期的相似性,威胁软件开发的相同软件供应链攻击途径也会对模型开发产生威胁:
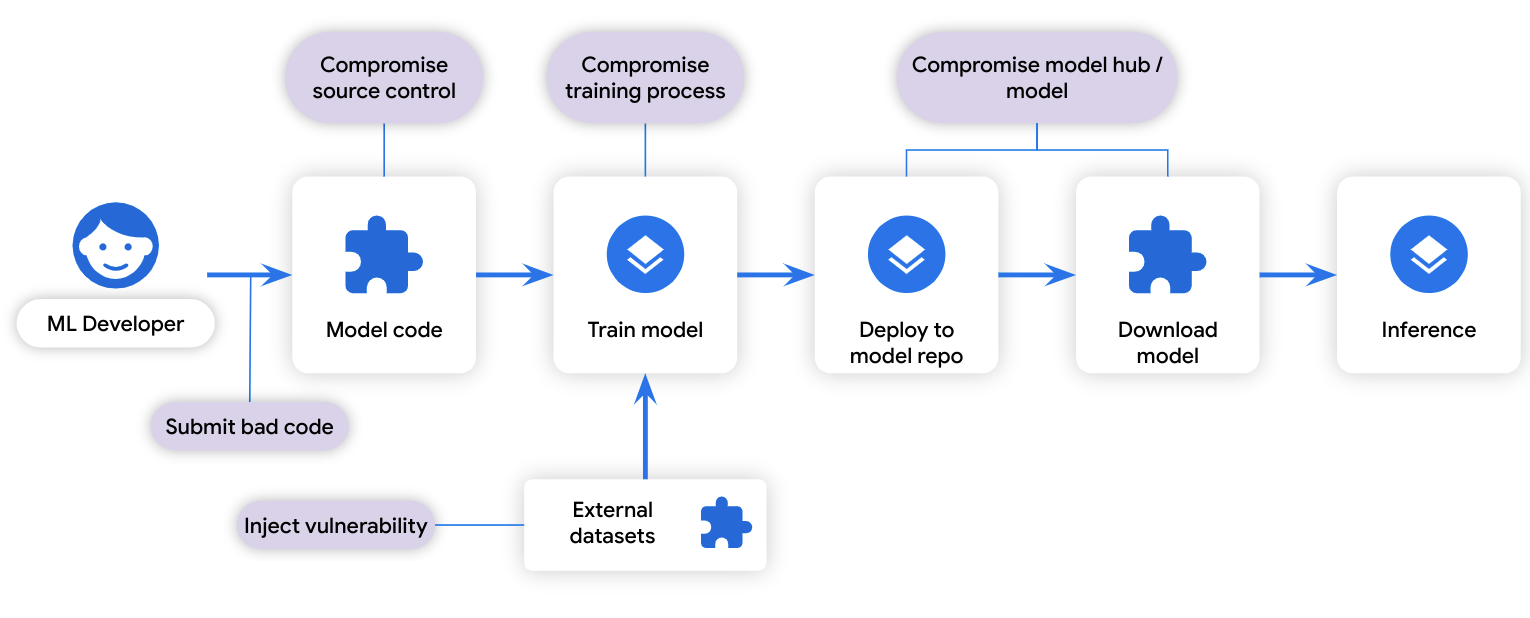
△ 通过 ML 供应链形成的 ML 攻击途径
基于开发生命周期和威胁途径的相似性,我们建议为 ML 模型应用相同的 SLSA 和 Sigstore 供应链解决方案,以相似的方法保护 ML 模型免受供应链攻击。
适用于 ML 模型的 Sigstore
代码签名是确保供应链安全的关键步骤。它可以识别软件的提供方,并防止软件发布后被篡改。但代码签名通常难以设置,因为提供方需要管理和轮换密钥,设置验证基础设施,并为消费者提供验证方法指导。由于在此过程中很难确保安全性,因此密钥通常也容易被泄露。
我们建议使用 Sigstore 来绕开这些挑战,Sigstore 可以提供一系列服务和工具,让代码签名变得安全且轻松。利用 Sigstore,软件提供方只需使用绑定到工作负载或开发者身份的 OpenID Connect 令牌即可对软件签名,无需管理或轮换长期密钥。
那么,对 ML 模型签名可以给用户带来哪些好处?通过在训练后对模型签名,我们可以向用户保证,他们拥有的模型即是构建者 (又称 "训练者") 上传的模型。对模型进行签名让模型中心所有者无法更换模型,这解决了模型中心遭受攻击的问题,并有助于防止用户被欺骗使用不良模型。
模型签名让类似于 PoisonGPT 的攻击可以被检测到。被篡改的模型无法完成签名验证,或者可以用于直接追溯恶意操作者。我们目前为推广此业界标准开展了以下方面的工作:
- 让 ML 框架在模型保存/加载 API 时集成签名和验证;
- 让 ML 模型中心为所有已签名的模型添加徽章标志,从而引导用户选择已签名的模型并激励模型开发者进行签名;
- 拓展 LLM 模型签名。
用于 ML 供应链完整性的 SLSA
使用 Sigstore 签名可以让用户对他们正在使用的模型更有信心,但这种方式无法解答他们对模型的所有疑问。SLSA 则进一步为这些签名赋予了更多意义。
SLSA (软件工件的供应链级别) 是一种描述软件工件开发方式的规范。支持 SLSA 的构建平台采取各种控制措施,以防遭到篡改,并输出签名来源,描述软件工件的生成过程,包括所有构建输入。通过这种方式,SLSA 能够提供有关软件工件内容的可信元数据。
将 SLSA 应用于 ML 可以提供有关 ML 模型供应链的类似信息,并解决模型签名未涵盖的攻击途径问题,例如受损的源代码控制、受损的训练过程和漏洞注入。我们的愿景是在 SLSA 来源文件中包含特定的 ML 信息,从而帮助用户发现训练不足的模型或根据不良数据训练的模型。当检测到 ML 框架存在漏洞时,用户可以快速确定需要重新训练的模型,从而降低成本。
我们不需要为 SLSA 设置特别的 ML 扩展。ML 训练过程是一种构建过程 (如前图所示),因此我们可以将现有 SLSA 指南应用于 ML 训练。ML 训练过程应该像传统构建过程一样,针对篡改和输出来源问题进行强化。要让 SLSA 充分发挥作用并适用于 ML,我们还需要 做更多工作,特别是在描述数据集和预训练模型等依赖项方面。大部分工作同样也将会有益于传统软件。
对于在不需要 GPU/TPU 的流水线上进行的模型训练,使用支持 SLSA 的现有构建平台不失为一个简单的解决方案。例如,Google Cloud Build、GitHub Actions 与 GitLab CI 都是通用的可支持 SLSA 的构建平台。您可以在其中一个平台上运行 ML 训练步骤,让所有内置的供应链安全功能可用于传统软件。
如何立即为 ML 启用模型签名和 SLSA
供应链安全现已被纳入 ML 开发生命周期中,虽然问题空间仍在不断拓展,但我们可以与开源社区携手合作,共同制定业界标准来解决紧迫的问题。这项工作已经在进行中,并且可供测试。
我们的工具库 现已推出,旨在为小型 ML 模型提供模型签名和实验性 SLSA 来源支持。未来,我们的 ML 框架和模型中心集成也将在此工具库中发布。
我们很高兴能与 ML 社区合作,并期待就如何以最佳方式将供应链保护标准与现有工具 (如 Model Cards) 集成的问题达成共识。如果您 有任何问题、反馈或想法,欢迎随时分享给我们。也欢迎您持续关注我们,及时获悉更多资讯。

原文:Increasing transparency in AI security
中文:TensorFlow 公众号
 微信赞赏
微信赞赏 支付宝赞赏
支付宝赞赏
相关文章

