引言
本教程将向你展示在不编写一行代码的情况下,如何构建自己的开源 ChatGPT,这样人人都能构建自己的聊天模型。我们将以 LLaMA 2 基础模型为例,在开源指令数据集上针对聊天场景对其进行微调,并将微调后的模型部署到一个可分享的聊天应用中。全程只需点击鼠标,即可轻松通往荣耀之路!😀
为什么这很重要?是这样的,机器学习,尤其是 LLM (Large Language Models,大语言模型),已前所未有地普及开来,渐渐成为我们生产生活中的重要工具。然而,对非机器学习工程专业的大多数人来说,训练和部署这些模型的复杂性似乎仍然遥不可及。如果我们理想中的机器学习世界是充满着无处不在的个性化模型的,那么我们面临着一个迫在眉睫的挑战,即如何让那些没有技术背景的人独立用上这项技术?
在 Hugging Face,我们一直在默默努力为这个包容性的未来铺平道路。我们的工具套件,包括 Spaces、AutoTrain 和 Inference Endpoints 等服务,就是为了让任何人都能进入机器学习的世界。
为了展示这个民主化的未来是何其轻松,本教程将向你展示如何使用 Spaces、AutoTrain 和 ChatUI 构建聊天应用。只需简单三步,代码含量为零。声明一下,我们也不是机器学习工程师,而只是 Hugging Face 营销策略团队的一员。如果我们能做到这一点,那么你也可以!话不多说,我们开始吧!
Spaces 简介
Hugging Face 的 Spaces 服务提供了易于使用的 GUI,可用于构建和部署 Web 托管的 ML 演示及应用。该服务允许你使用 Gradio 或 Streamlit 前端快速构建 ML 演示,将你自己的应用以 docker 容器的形式上传,甚至你还可以直接选择一些已预先配置好的 ML 应用以实现快速部署。
后面,我们将部署两个来自 Spaces、AutoTrain 和 ChatUI 的预配置 docker 应用模板。
你可参阅 此处,以获取有关 Spaces 的更多信息。
AutoTrain 简介
AutoTrain 是一款无代码工具,可让非 ML 工程师 (甚至非开发人员😮) 无需编写任何代码即可训练最先进的 ML 模型。它可用于 NLP、计算机视觉、语音、表格数据,现在甚至可用于微调 LLM,我们这次主要用的就是 LLM 微调功能。
你可参阅 此处,以获取有关 AutoTrain 的更多信息。
ChatUI 简介
ChatUI 顾名思义,是 Hugging Face 构建的开源 UI,其提供了与开源 LLM 交互的界面。值得注意的是,它与 HuggingChat 背后的 UI 相同,HuggingChat 是 ChatGPT 的 100% 开源替代品。
你可参阅 此处,以获取有关 ChatUI 的更多信息。
第 1 步: 创建一个新的 AutoTrain Space
1.1 在 huggingface.co/spaces 页面点击 “Create new Space” 按钮。
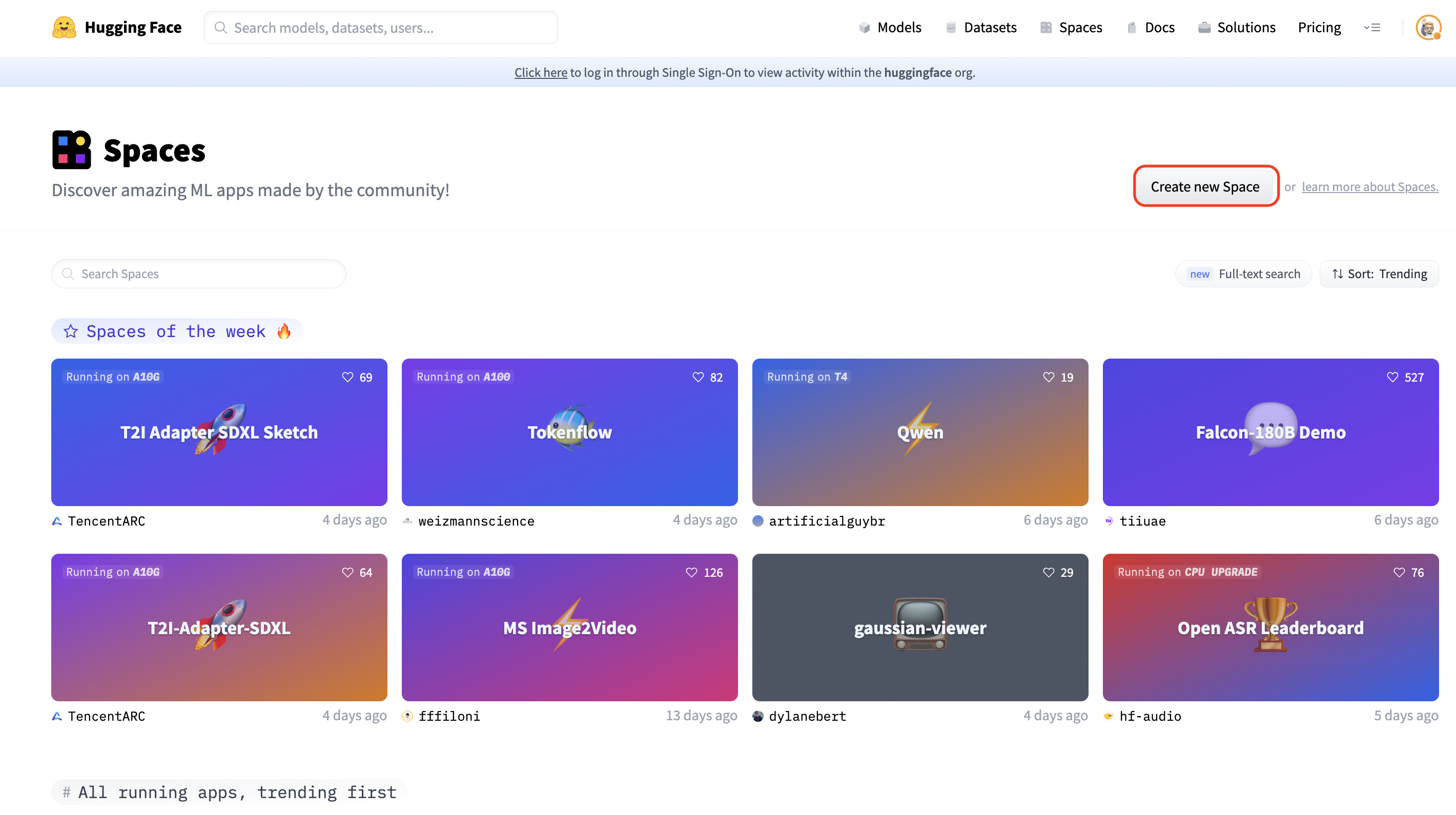
1.2 如果你计划公开这个模型或 Space,请为你的 Space 命名并选择合适的许可证。
1.3 请选择 Docker > AutoTrain,以直接用 AutoTrain 的 docker 模板来部署。
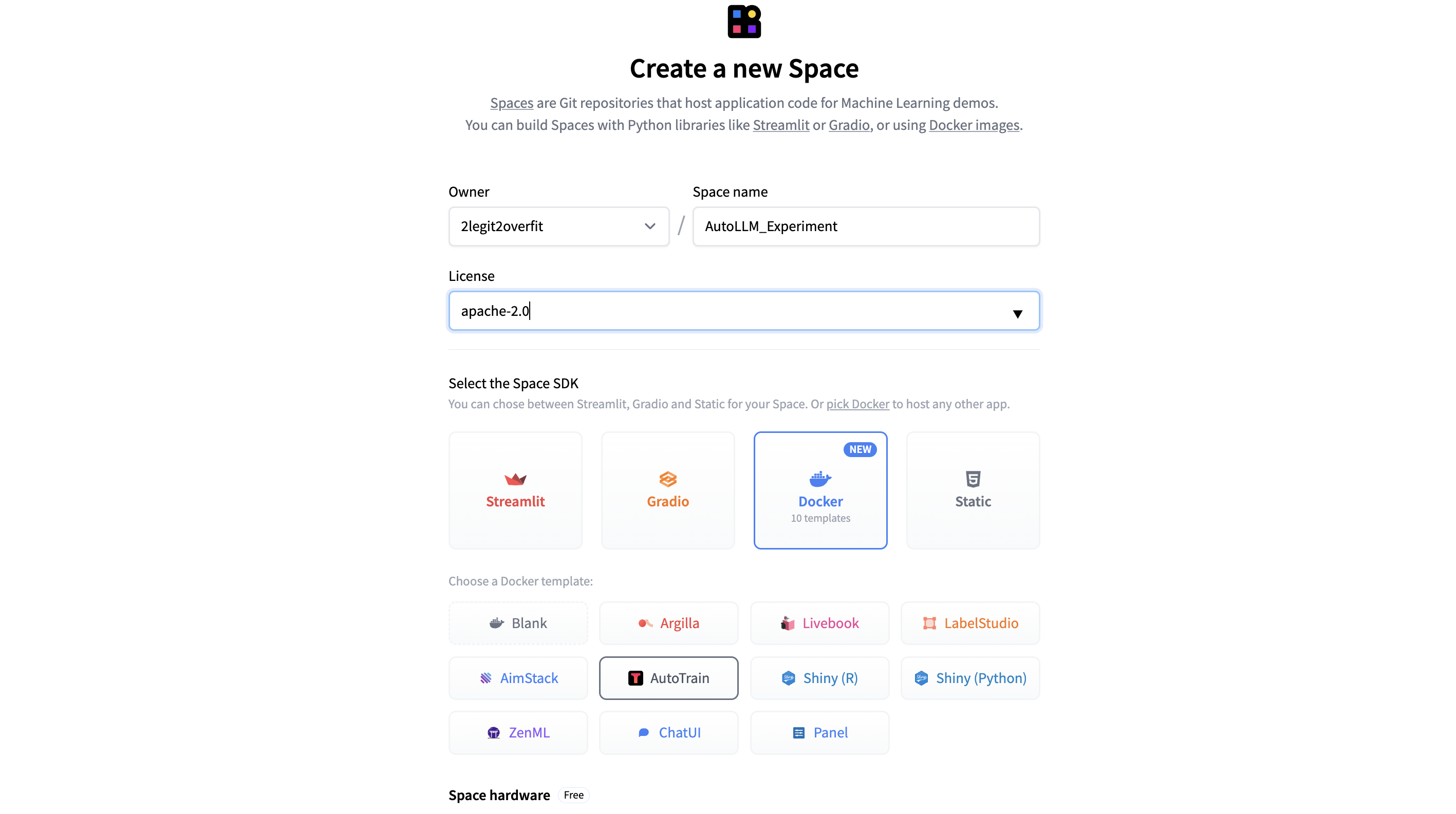
1.4 选择合适的 “Space hardware” 以运行应用。(注意: 对于 AutoTrain 应用,免费的 CPU 基本款就足够了,模型训练会使用单独的计算来完成,我们稍后会进行选择)。
1.5 在 “Space secrets” 下添加你自己的 “HF_TOKEN”,以便让该 Space 可以访问你的 Hub 帐户。如果没有这个,Space 将无法训练或将新模型保存到你的帐户上。(注意: 你可以在 “Settings > Access Tokens” 下的 “Hugging Face Profile” 中找到你的 HF_TOKEN ,请确保其属性为 “Write”)。
1.6 选择将 Space 设为“私有”还是“公开”,对于 AutoTrain Space 而言,建议设为私有,不影响你后面公开分享你的模型或聊天应用。
1.7 点击 “Create Space” 并稍事等待!新 Space 的构建需要几分钟时间,之后你就可以打开 Space 并开始使用 AutoTrain。
第 2 步: 在 AutoTrain 中启动模型训练
2.1 AutoTrain Space 启动后,你会看到下面的 GUI。AutoTrain 可用于多种不同类型的训练,包括 LLM 微调、文本分类、表格数据以及扩散模型。我们今天主要专注 LLM 训练,因此选择 “LLM” 选项卡。
2.2 从 “Model Choice” 字段中选择你想要训练的 LLM,你可以从列表中选择模型或直接输入 Hugging Face 模型卡的模型名称,在本例中我们使用 Meta 的 Llama 2 7B 基础模型,你可从其 模型卡 处了解更多信息。(注意: LLama 2 是受控模型,需要你在使用前向 Meta 申请访问权限,你也可以选择其他非受控模型,如 Falcon)。
2.3 在 “Backend” 中选择你要用于训练的 CPU 或 GPU。对于 7B 模型,“A10G Large” 就足够了。如果想要训练更大的模型,你需要确保该模型可以放进所选 GPU 的内存。(注意: 如果你想训练更大的模型并需要访问 A100 GPU,请发送电子邮件至 [email protected])。
2.4 当然,要微调模型,你需要上传 “Training Data”。执行此操作时,请确保数据集格式正确且文件格式为 CSV。你可在 此处 找到符合要求的格式的例子。如果你的数据有多列,请务必选择正确的 “Text Column” 以确保 AutoTrain 抽取正确的列作为训练数据。本教程将使用 Alpaca 指令微调数据集,你可在 此处 获取该数据集的更多信息。你还可以从 此处 直接下载 CSV 格式的文件。
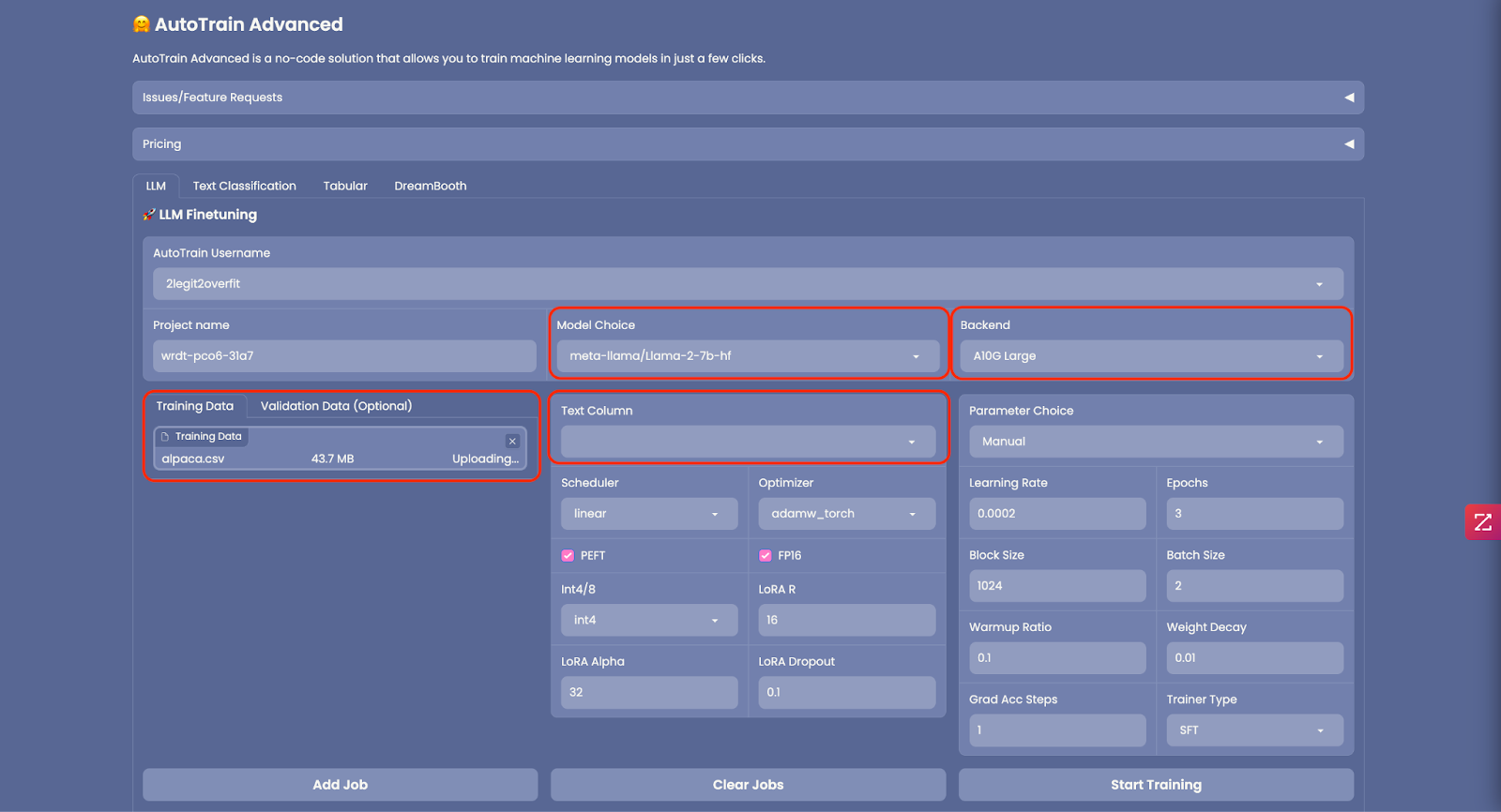
2.5 【可选】 你还可以上传 “Validation Data” 以用于测试训出的模型,但这不是必须的。
2.6 AutoTrain 中有许多高级设置可用于减少模型的内存占用,你可以更改精度 (“FP16”) 、启用量化 (“Int4/8”) 或者决定是否启用 PEFT (参数高效微调)。如果对此不是很精通,建议使用默认设置,因为默认设置可以减少训练模型的时间和成本,且对模型精度的影响很小。
2.7 同样地,你可在 “Parameter Choice” 中配置训练超参,但本教程使用的是默认设置。
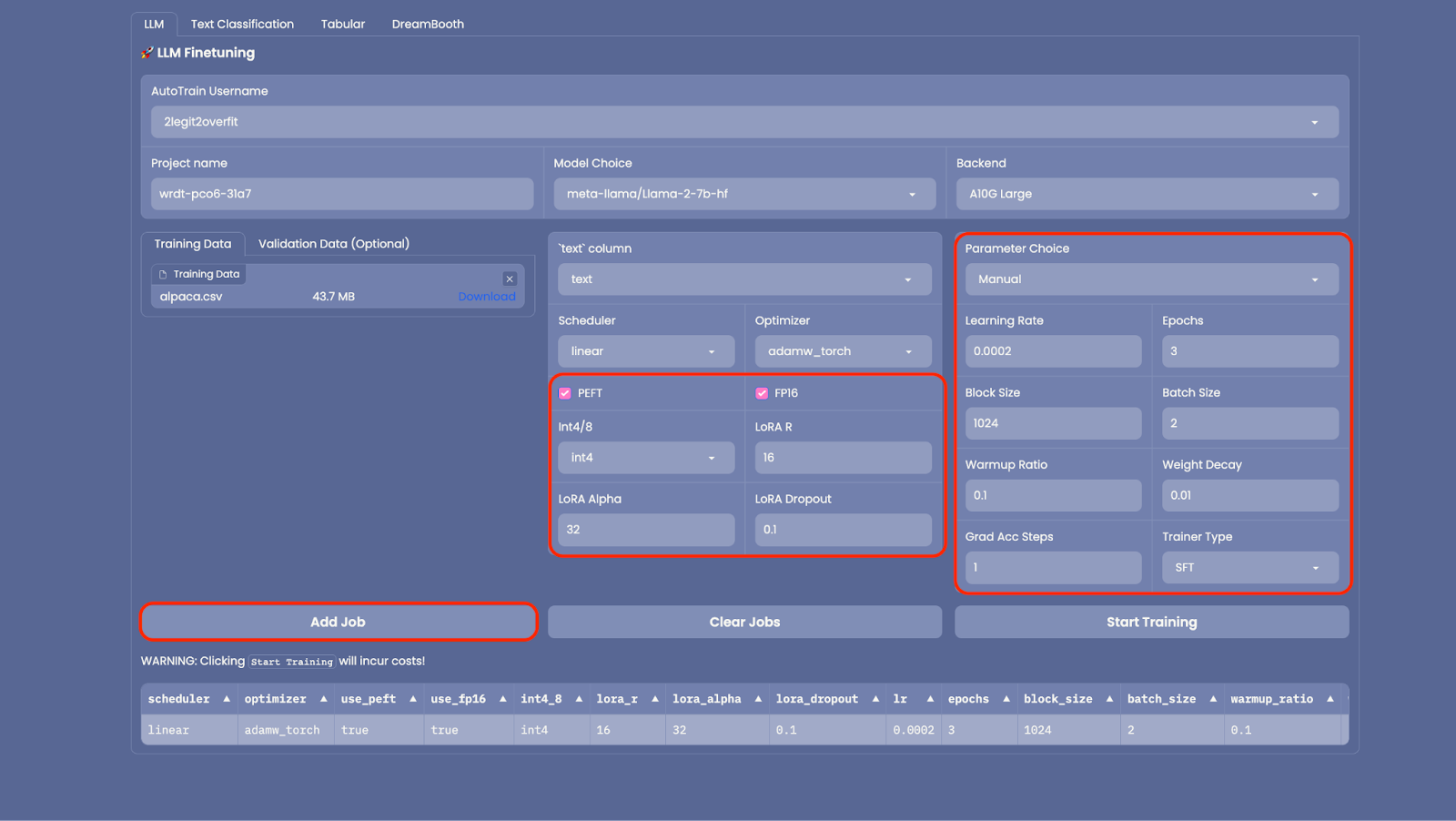
2.8 至此,一切都已设置完毕,点击 “Add Job” 将模型添加到训练队列中,然后点击 “Start Training”(注意: 如果你想用多组不同超参训练多个版本的模型,你可以添加多个作业同时运行)。
2.9 训练开始后,你会看到你的 Hub 帐户里新创建了一个 Space。该 Space 正在运行模型训练,完成后新模型也将显示在你 Hub 帐户的 “Models” 下。(注: 如欲查看训练进度,你可在 Space 中查看实时日志)。
2.10 去喝杯咖啡。训练可能需要几个小时甚至几天的时间,这取决于模型及训练数据的大小。训练完成后,新模型将出现在你的 Hugging Face Hub 帐户的 “Models” 下。
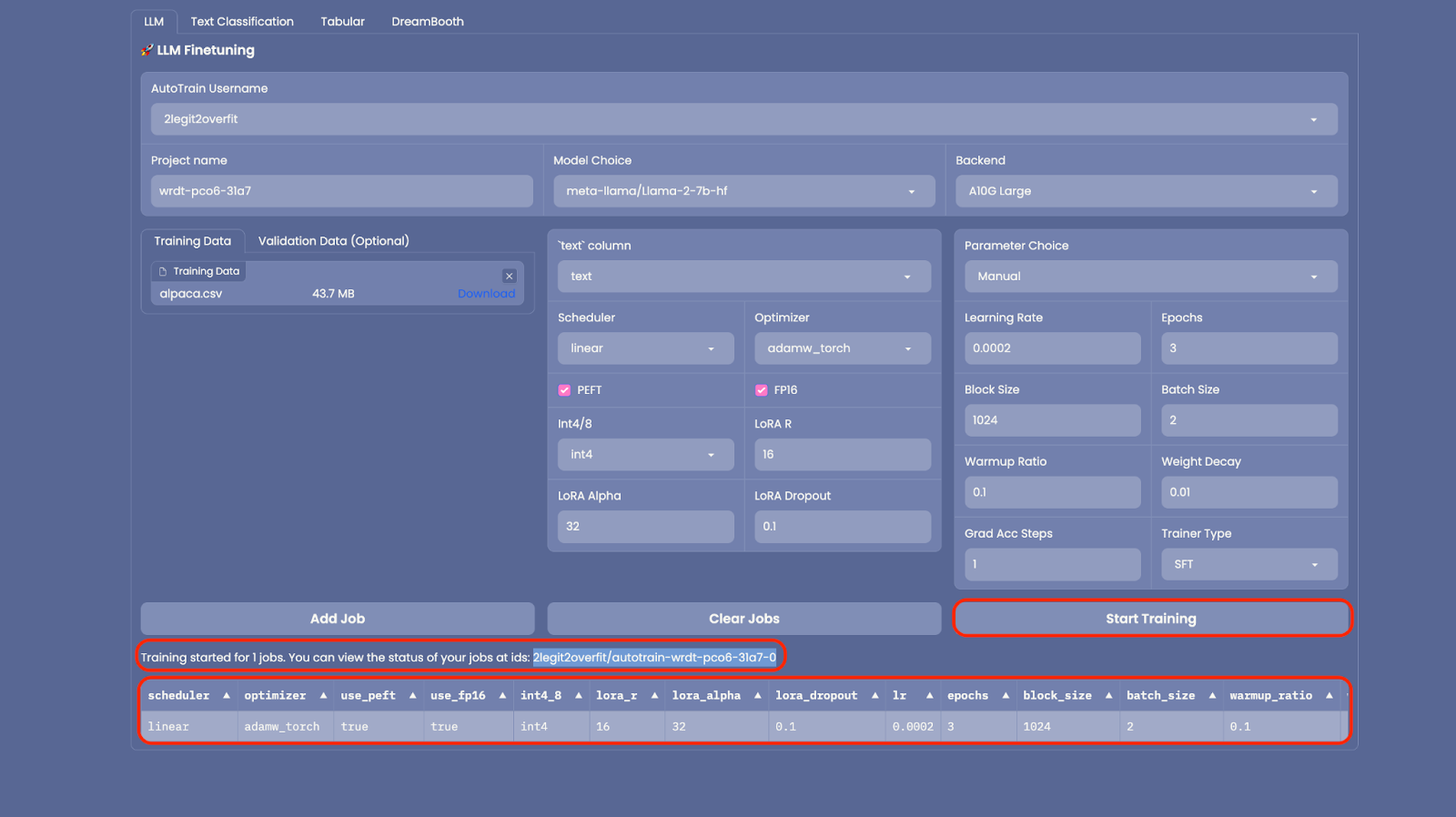
第 3 步: 使用自己的模型创建一个新的 ChatUI Space
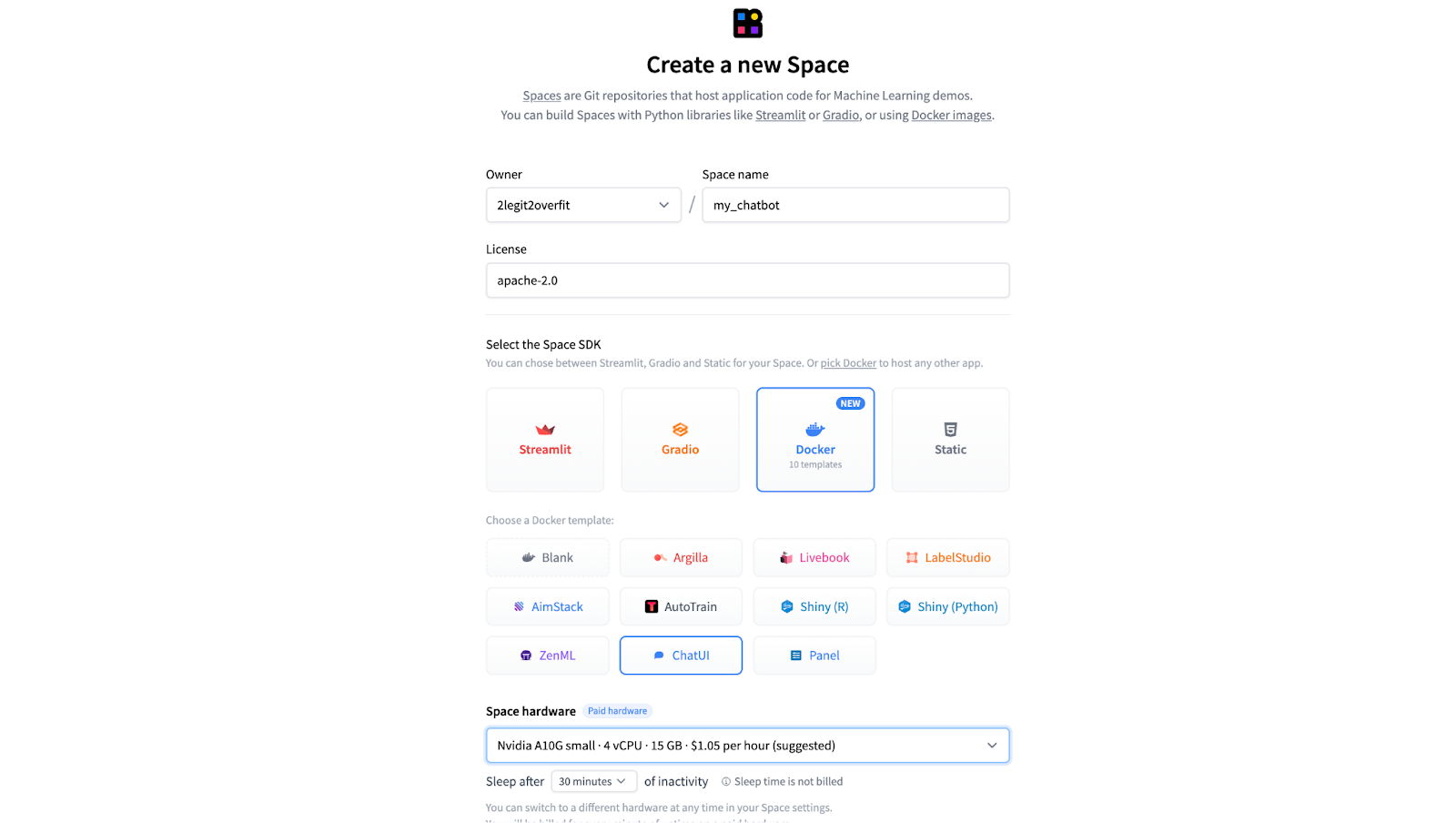
3.1 按照与步骤 1.1 > 1.3 相同的流程设置新 Space,但选择 ChatUI docker 模板而不是 AutoTrain。
3.2 选择合适的 “Space Hardware”,对我们用的 7B 模型而言 A10G Small 足够了。注意硬件的选择需要根据模型的大小而有所不同。
3.3 如果你有自己的 Mongo DB,你可以填入相应信息,以便将聊天日志存储在 “MONGODB_URL” 下。否则,将该字段留空即可,此时会自动创建一个本地数据库。
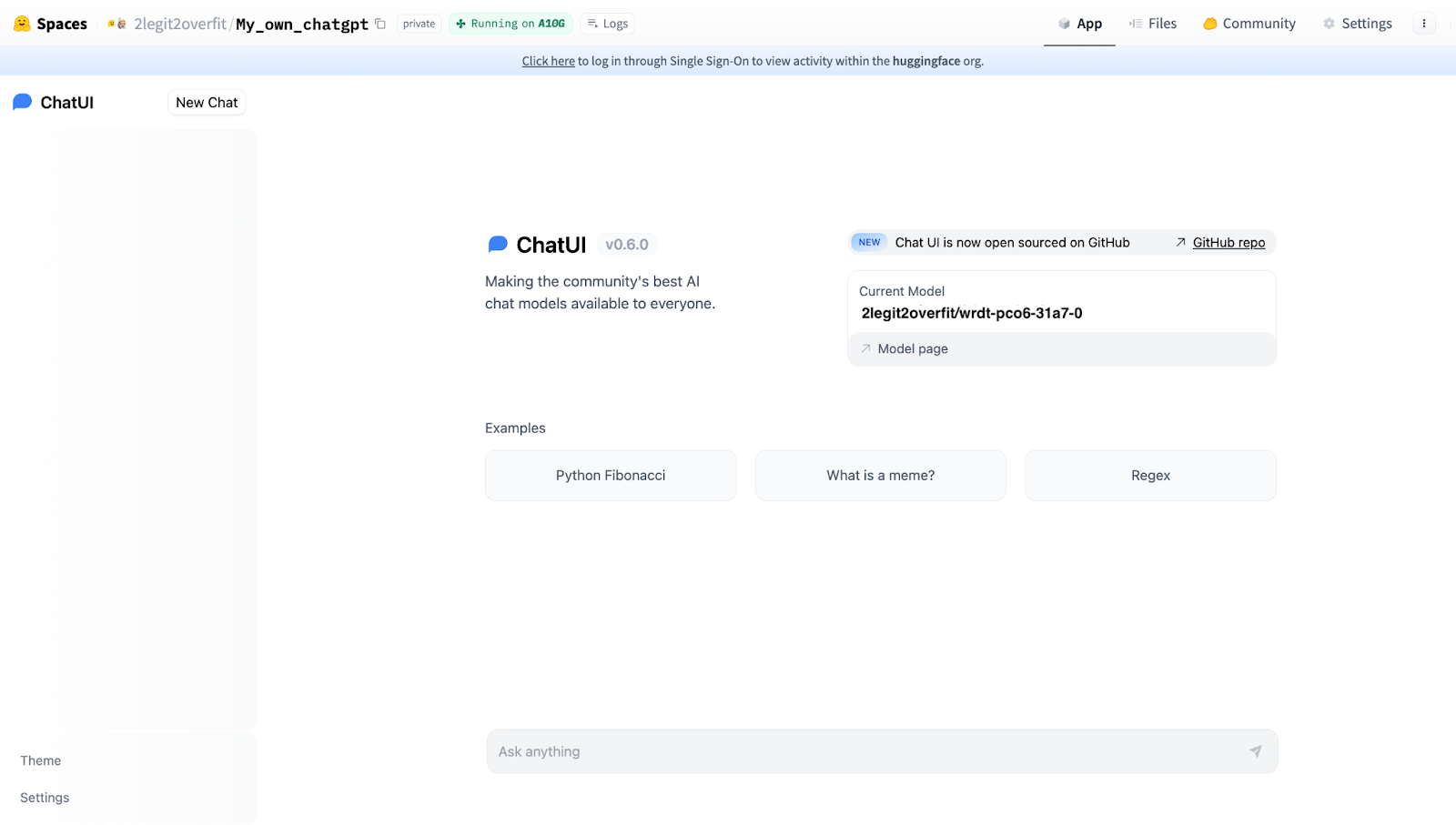
3.4 为了能将训后的模型用于聊天应用,你需要在 “Space variables” 下提供 “MODEL_NAME”。你可以通过查看你的 Hugging Face 个人资料的 “Models” 部分找到模型的名称,它和你在 AutoTrain 中设置的 “Project name” 相同。本例中模型的名称为 “2legit2overfit/wrdt-pco6-31a7-0”。
3.5 在 “Space variables” 下,你还可以更改模型的推理参数,包括温度、top-p、生成的最大词元数等文本生成属性。这里,我们还是直接使用默认设置。
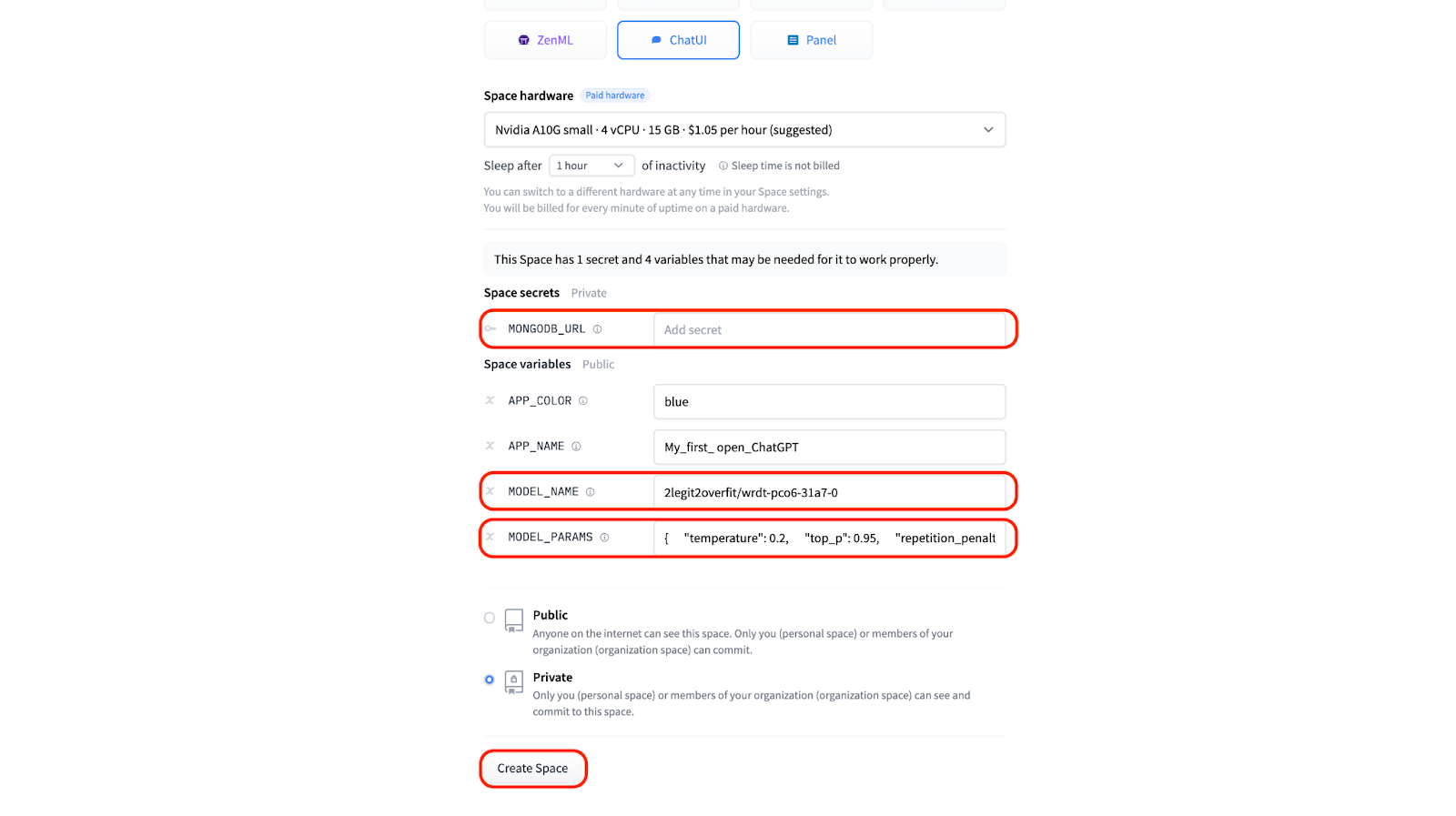
3.6 现在,你可以点击 “Create” 并启动你自己的开源 ChatGPT,其 GUI 如下。恭喜通关!
如果你看了本文很想尝试一下,但仍需要技术支持才能开始使用,请随时通过 此处 联系我们并申请支持。 Hugging Face 提供付费专家建议服务,应该能帮到你。
赞赏英文原文: https://hf.co/blog/Llama2-for-non-engineers
原文作者: Andrew Jardine,Abhishek Thakur
译者: Matrix Yao (姚伟峰),英特尔深度学习工程师,工作方向为 transformer-family 模型在各模态数据上的应用及大规模模型的训练推理。
 微信赞赏
微信赞赏 支付宝赞赏
支付宝赞赏
相关文章

